Discussion modèle:Infobox Langue
- Admissibilité
- Neutralité
- Droit d'auteur
- Article de qualité
- Bon article
- Lumière sur
- À faire
- Archives
- Commons
Suppression de la ligne SIL, ajout de la ligne IETF modifier
Bonjour, je viens d'observer les résultats de ces deux changements sur l'article Auvergnat. Sur la suppression de SIL, j'allais la proposer, le code SIL étant depuis Ethnologue 16 (2009) aligné sur le code ISO 639-3. Sur l'ajout d'IETF, ce point a-t-il été discuté quelque part ? --Jean-François Blanc (d) 10 septembre 2009 à 09:36 (CEST)
- Après vérification, je fais un revert sur le modèle : modif faite par une adresse IP, aucune explication. --Jean-François Blanc (d) 10 septembre 2009 à 12:43 (CEST)
Proposition d'Ajout d'une ligne Système d'écriture modifier
Bonjour,
Ne serait-il pas judicieux d'avoir une ligne dans l'infobox langue, précisant le système d'écriture? Merci de vos participations. --Matfran (d) 1 avril 2010 à 11:12 (CEST)François
Ajout d'un champ pour une carte ? modifier
Apparemment aucun champ n'est prévu pour inclure une carte de répartition. C'est dommage, voir Langues romanes.
Quelqu'un peut-il en rajouter ? Bibi Saint-Pol (sprechen) 18 septembre 2010 à 23:00 (CEST)
- Les cartes présentes dans les articles ne rentrent pas dans l'infobox (trop larges). Si on les réduit elles auront leurs détails illisibles. Visite fortuitement prolongée (d) 19 septembre 2010 à 14:56 (CEST)
Champs « parlée » vs « aire » (linguistique) modifier
Il est pratique de disposer d'un champ qui ne se limite pas aux subdivisions administratives (répertoriées par les champs « pays » et « région »). En effet, il est parfois absurde de localiser les langues par le biais de la géopolitique actuelle, notamment pour les langues disparues. Le champ « parlée » convient pour cela, mais il s'applique malheureusement de façon restrictive aux langues vivantes. Un champ « aire » (linguistique) permettrait de corriger ce défaut. Baleer (d) 17 mai 2011 à 22:33 (CEST)
Liste déroulante ? modifier
Bonjour.
J'ai remarqué que assez souvent le paramètre pays est très long comme pour Français. Ce serait pas plus pratique de mettre une liste déroulante comme c'est le cas dans l'infobox billet ? (exemple ici). --Woozz un problème? 11 mai 2012 à 06:19 (CEST)
- Bonne idée. Je rajoute la suggestion dans la documentation du modèle. Aucassin (discuter) 28 août 2014 à 15:30 (CEST)
Code Linguasphere modifier
Le code Linguasphere ne me semble pas notoire. Visite fortuitement prolongée (d) 24 mai 2013 à 22:21 (CEST)
- Merci d'expliquer clairement. L'Observatoire linguistique Linguasphère est un organisme reconnu et toute information supplémentaire peut être bénéfique au lecteur.
- Cordialement, — Şÿℵדαχ₮ɘɼɾ๏ʁ You talkin' to me? 3 juin 2014 à 07:38 (CEST)
- Je ne vois pas non plus de raison de ne pas inclure ce code. Aucassin (discuter) 28 août 2014 à 14:56 (CEST)
Puisqu'il s'agit d'en établir la notabilité, deux revues :
- Edward J. Vajda, The Linguasphere Register of the World's Languages and Speech Communities (review). In : Language (Linguistic Society of America), vol. 77, n° 3, 2001, p. 606–608. Accès MUSE
- Anthony P. Grant, Book Review. Dalby, David. The Linguasphere register of the world's languages and speech communities, 1999. In : Journal of the Royal Anthropological Institute, vol.9 , n° 2, 2003 , p.387-388 Accès Wiley
usage comme référence par l'Unesco
- Investing in Cultural Diversity and Intercultural Dialogue. UNESCO world report, vol. 2. Unesco, 2009. (World Report Series). 402 p. (ISBN 9231040774 et 9789231040771). Accès Google Books, voir la p. 90
et diverses citations recueillies sur Google Scholar (passer la première page où les citations sont essentiellement internes) [1]
Cela suffit. Aucassin (discuter) 28 août 2014 à 23:26 (CEST)
Champ pour le World Atlas of Language Structures modifier
J'ajoute un champ pour lier vers cette base de données de première importance en typologie et de portée globale.
Citations sur GoogleScholar [2].
Numéro spécial dans Language Typology and Universals :Volume 61, Issue 3 (Aug 2008). Introduction : Michael Cyxouw, Using the World Atlas of Language Structures. STUF - Language Typology and Universals Sprachtypologie und Universalienforschung. Volume 61, Issue 3, Pages 181–185, ISSN (Print) 0942-2919, DOI: 10.1524/stuf.2008.0018, September 2009 page éditeur
Citation de l'importance de cette base pour la recherche actuelle en typologie : Balthasar Bickel, Typology in the 21st century: Major current developments. Linguistic Typology. Volume 11, Issue 1, Pages 239–251, ISSN (Online) 1613-415X, ISSN (Print) 1430-0532, DOI: 10.1515/LINGTY.2007.018, July 2007 page éditeur article en accès libre
Intitulé du champ pays modifier
Je propose de modifier l'intitulé du champ « pays » en Pays plutôt que Parlée en pour les raisons suivantes :
- clarifier son usage par rapport au champ « région », dont la documentation de l'infobox recommande l'usage quand il est malaisé ou peu pertinent de donner une liste de pays, ou pour compléter quand une langue n'est parlée que dans une partie d'un pays.
- éviter le problème du choix de la préposition, qui représente une complication inutile requérant un champ « parlée » pas toujours utilisé à bon escient
- éviter les problème d'accord au pluriel (actuellement non pris en compte) quand l'infobox est employée pour une famille de langues : voir par exemple le problème que cela pose dans langues mayas.
Aucassin (discuter) 16 septembre 2014 à 11:34 (CEST)
- Je n'ai jamais bien compris la raison pour laquelle l'infoboîte s'embarrassait de ces complexités. J'approuve l'idée, mais pourquoi ne pas aller jusqu'au bout et carrément fusionner les champs « Parlée en » et « Région » ? Est-il vraiment indispensable d'avoir deux champs géographiques ? – Swa cwæð Ælfgar (discuter) 17 septembre 2014 à 11:34 (CEST)
- Je suis d’accord que ces champs doublonnent souvent et sont mal utilisés, mais il ne me semble pas toujours inutile pour autant d’en avoir deux si leur usage est mieux défini. Notamment, quand la langue est parlée dans une région bien définie mais inconnue du grand public, le champ région permet de jouer la précision, le champ pays d’avoir une indication plus générale et familière : ex. l’erzya (parlé en Mordovie), le mwotlap (parlé à Mota Lava), le candoshi (parlé dans la région de Loreto), etc. D’où ma proposition de clarifier les choses en ayant clairement 1) le pays, où ne devraient entrer que des noms d'États (redoublant plus ou moins la catégorisation des langues par pays) 2) la région, quand la précision est utile ou que le champ pays est d'usage malaisé. « Parlé en » ne fait qu'entretenir l'ambiguïté, en plus de poser des problèmes de grammaire qui nous encombrent d'un troisième champ.
- Et puis (et surtout) il y a le point de vue pratique... autant renommer l’intitulé d’un champ est rapide, fusionner ces deux-là est une autre affaire, vu le passif et le nombre de pages concernées ! Aucassin (discuter) 17 septembre 2014 à 17:18 (CEST)
Lien automatique vers les pages de description des codes ISO 639-3 et ISO 639-5 modifier
J'ai intégré aux champs « iso3 » et « iso5 » le modèle {{Lien ISO 639-3}}, de sorte qu'un lien soit fait automatiquement vers la page web de description du code. Un passage de bot a permis de supprimer les modèles préalablement mis en place à la main, évitant l'inclusion du modèle dans lui-même.
Il reste un problème, celui des langues auxquelles plusieurs codes sont applicables. J'ai modifié le modèle {{Lien ISO 639-3}} qui permet maintenant de prendre en charge plusieurs codes, mais ça n'a pas l'air de marcher au sein de l'infobox. Je vais en référer au Projet:Infobox pour avoir un coup de main. Ci-dessous, la liste des pages posant problème. Aucassin (discuter) 16 septembre 2014 à 12:12 (CEST)
liste des pages posant problème
|
- code générique
- code générique
- ces codes ne couvrent pas tous les dialectes bétés
- code générique
- Le renvoi automatique vers les pages de description des codes ISO 639 empêchant d'ajouter une note sans tout casser, j'ai ajouté un nouveau champ libre notecode destiné à recueillir au besoin les diverses remarques sur les codes. Voir des exemples d'emploi sur les pages karagasse et créole dominiquais. Aucassin (discuter) 26 septembre 2014 à 12:44 (CEST)
- Qu'est-ce qui justifie d'afficher les notes dans l'infobox et pas, plus dicrètement, dans les notes et références ?
- Qu'est-ce qui garantie que les indications de généricité ou d'obsolescence seront bien pris en compte par les lecteurs si non indiquées sur la même ligne (par un renvois en note) ?
- Comment un robot sait-il qu'un code est générique ou obsolète ?
- Comment le nouveau mécanisme gère les notes de l'article Comorien ?
- Comment le nouveau mécanisme gère les notes de l'article Langues wintuanes ?
- Visite fortuitement prolongée (discuter) 26 septembre 2014 à 22:16 (CEST)
- En pratique, les limites techniques : le système wiki n'interprète pas correctement une note imbriquée dans un appel de lien externe. Cet argument est réversible : qu'est-ce qui justifie de reléguer une annotation sur l'usage des codes en note de fin plutôt que tout près de l'information qu'elle concerne ?
- On part du principe que les lecteurs savent lire et ont une mémoire à court terme suffisante entre deux lignes d'une infobox.
- Un robot ne "sait" rien, il récupère une donnée standard telle qu'un code selon le format pour lequel il est programmé. Il ne sera pas capable de gérer une note s'il n'est pas prévu pour ce faire. Dans la situation actuelle, en ajoutant une note, vous cassez le format et rendez la donnée tout aussi inutilisable que son annotation.
- C'est un champ libre, qui donne la possible d'écrire tout ce qu'il sera nécessaire de notifier. Ce n'est effectivement pas interprétable par une machine. Pour cela, il faudrait avoir un jeu de notes standard à appeler au besoin. Je ne saurais pas développer ça, mais on peut essayer de le demander à un des projets techniques.
- Idem. Avec en plus une question 1) de pertinence des codes : nai pour North American Indian est d'une utilité douteuse ici tant il est générique 2) de de mise à jour : le code wit est obsolète et à retirer de l'article.
- Maintenant, si vous voulez faire avancer l'affaire, on attend vivement vos contributions constructives. Aucassin (discuter) 7 octobre 2014 à 00:16 (CEST)
- Concernant 4 et 5 : vous n'avez répondu que superficiellement à mes deux questions.
- Concernant les codes génériques « nai », « cai », « sai », c'est le plus souvent
 Dhegiha : qui est à l'origine de leur présence.
Dhegiha : qui est à l'origine de leur présence. - Concernant le code « wit » : je vous invite à consulter le paragraphe commençant par « des codes langues sont parfois supprimés » dans l'article Code de langue IETF.
- Visite fortuitement prolongée (discuter) 7 octobre 2014 à 22:23 (CEST)
- C'est çà. Au lieu d'être constructif comme on vous le demande, dénigrez - vous avez lu la Zizanie de Goscinny, apparemment. Ces codes prétendument de familles de langues, aussi bancals qu'incomplets , si je m'en souviens, c'est vous qui les avez introduits dans les infobox. Si je les ais mis c'est en copiant-collant des infobox, car comme Aucassin, je sais bien qu'ils n'ont strictement aucune valeur phylogénique. Dhegiha (discuter) 14 octobre 2014 à 20:43 (CEST)
- Où est-ce que je dénigre ? Visite fortuitement prolongée (discuter) 14 octobre 2014 à 23:37 (CEST)
- Dhegiha : Dans lesquels de mes propos prétendez vous que je dénigre ?
- Et envers qui ?
- Pour que ma phrase « Concernant les codes génériques nai, cai, sai, c'est le plus souvent Dhegiha : qui est à l'origine de leur présence. » soit du dénigrement envers vous, il eut fallu que j'eusse exprimé une opinion négative des codes génériques nai, cai, sai. Ais-je jamais émis la moindre opinion dépréciative envers ces codes ?
- Qui prétend que ces codes sont des codes de familles de langues ?
- Que voulez vous dire par « Ces codes [...] si je m'en souviens, c'est vous qui les avez introduits dans les infobox. » ? que c'est moi, et non pas vous, qui suis le plus souvent à l'origine de leur présence dans les articles ? que c'est moi qui suis toujours à l'origine de leur présence dans les articles ? que je suis à l'origine de leur présence dans Wikipédia fr ?
- Est-ce du dénigrement envers moi ?
- Quoi que cela veuille dire, quelles sont vos preuves que « Ces codes [...] si je m'en souviens, c'est vous [moi] qui les avez introduits dans les infobox. » ?
- Contestez vous être le plus souvent à l'origine de la présence des codes génériques nai, cai, ou sai, dans les articles ?
- Contestez vous avoir introduit les codes génériques nai, cai, ou sai, dans plusieurs dizaines d'articles; plus que tous les autres wikipédiens réunis ?
- Où avez vous exprimé la moindre opinion dépréciative envers ces codes avant le 7 octobre 2014 à 22:23 ?
- Si vous êtes la personne le plus souvent à l'origine de la présence de ces codes et si vous n'avez jamais critiqué leur présence, alors n'est-il pas logique de conclure, sinon que vous êtes attaché à leur présence, du moins que vous seriez intéressé à savoir que Aucassin veut peut-être les supprimer ? Ne serait-il pas alors logique, pertinent et aimable de vous prévenir par une notification ?
- Combien de codes génériques nai, cai, ou sai avez vous supprimés depuis le 7 octobre 2014 (dans Wikipédia fr) ?
- Il va de soit que vous pouvez barrer vos accusations et me présenter des excuses.
- Visite fortuitement prolongée (discuter) 26 octobre 2014 à 22:13 (CET)
- J'ai même pas lu, là…J'ai l'impression d'être un accusé dans un tribunal et d'entendre parler le procureur. Dhegiha (discuter) 27 octobre 2014 à 00:31 (CET)
- Super, on va pouvoir passer à autre chose. Visite fortuitement prolongée (discuter) 27 octobre 2014 à 22:18 (CET)
- J'ai même pas lu, là…J'ai l'impression d'être un accusé dans un tribunal et d'entendre parler le procureur. Dhegiha (discuter) 27 octobre 2014 à 00:31 (CET)
- C'est çà. Au lieu d'être constructif comme on vous le demande, dénigrez - vous avez lu la Zizanie de Goscinny, apparemment. Ces codes prétendument de familles de langues, aussi bancals qu'incomplets , si je m'en souviens, c'est vous qui les avez introduits dans les infobox. Si je les ais mis c'est en copiant-collant des infobox, car comme Aucassin, je sais bien qu'ils n'ont strictement aucune valeur phylogénique. Dhegiha (discuter) 14 octobre 2014 à 20:43 (CEST)
Type et étendue des codes ISO 639-3 et ISO 639-5 modifier
Je ne comprend pas pourquoi ces données sont collectées (et facilement sourçables par la page de description des codes, automatiquement liée) mais pas affichées. J'en rétablis l'affichage. Aucassin (discuter) 26 septembre 2014 à 14:48 (CEST)
La norme ISO 639 a pour titre « Codes pour la représentation des noms de langues ». Les valeurs « type » et « étendue » ne sont ni des noms de langue ni des codes. À ma connaissance aucun organisme linguistique ou normatif n'a vérifié ou confirmé ces valeurs, qui ne sont qu'une facilité administrative. Leur notoriété restant à prouver, un linguiste a-t-il recommandé ou utilisé ces données ? Visite fortuitement prolongée (discuter) 27 septembre 2014 à 22:12 (CEST)
- À ma connaissance, c'est juste de la cuisine interne à ISO 639, et n'a jamais été avalisé par aucun linguiste. Accessoirement, Wikipédia en anglais n'affiche pas ces informations dans le modèle équivalent en:Template:Infobox language. Visite fortuitement prolongée (discuter) 26 octobre 2014 à 22:10 (CET)
- « La norme ISO 639 a pour titre « Codes pour la représentation des noms de langues ». Les valeurs « type » et « étendue » ne sont ni des noms de langue ni des codes. À ma connaissance aucun organisme linguistique ou normatif n'a vérifié ou confirmé ces valeurs, qui ne sont qu'une facilité administrative. »
- Il ne vous aura pas échappé que l'ISO 639 dépend de l'Organisation internationale de normalisation, qui est un organisme normatif par vocation ? Mais il est exact que la notion de macro-langue a été créée pour l'ISO 639-3 et a du sens dans ce cadre là. Les propriétés attachées à un code sont importantes pour en assurer l'usage correct, mais à partir du moment où l'on peut accéder à la page de description du code, ce qui est maintenant automatique, on peut estimer que c'est suffisant, quoique ce soit inutilement mettre l'information à un clic de plus. Aucassin (discuter) 28 octobre 2014 à 23:23 (CET)
- Vous ne répondez pas à mes propos sur l'intitulé de la norme ISO 639.
- Vous ne répondez quasiment pas (avec « Mais il est exact que la notion de macro-langue a été créée pour l'ISO 639-3 et a du sens dans ce cadre là. ») à mes propos sur la valeur des données « type » et « étendue ».
- « Il ne vous aura pas échappé que l'ISO 639 dépend de l'Organisation internationale de normalisation, qui est un organisme normatif par vocation ? » → Non, cela ne m'a pas échappé.
- « Les propriétés attachées à un code sont importantes pour en assurer l'usage correct » → Les articles sur des langues ne sont pas des articles sur des codes de langues. Les détails opérationnels tels la date de mise en service, le type ISO 639-2 ou le type ISO 639-3 n'ont à mon avis pas leur place dans les articles sur des langues. D'ailleurs j'ai supprimé tous les types ISO 639-2. Par contre il est possible (Wikipédia:N'hésitez pas !) de créer des articles sur des codes de langues. ISO 639:nor et ISO 639:zho existent déjà.
- « Mais il est exact que la notion de macro-langue a été créée pour l'ISO 639-3 et a du sens dans ce cadre là. Les propriétés attachées à un code sont importantes pour en assurer l'usage correct, mais à partir du moment où l'on peut accéder à la page de description du code, ce qui est maintenant automatique, on peut estimer que c'est suffisant, quoique ce soit inutilement mettre l'information à un clic de plus. » Si cela signifie que vous acceptez que les paramètres « type » et « étendue » restent masqués, alors c'est une bonne chose à mon avis.
- Visite fortuitement prolongée (discuter) 30 octobre 2014 à 22:21 (CET)
- Vous pensez réellement que le contenu d'une norme se résume en un titre ? Qu'un simple code justifierait d'un article séparé, alors que vous savez très bien qu'ils n'ont d'intérêt que vis-à-vis de la langue en question dans son contexte, qu'ils ne seraient vraisemblablement, et à bon droit, pas jugés admissibles en tant qu'articles ? Alors même que vous n'avez de cesse que de vous opposer à ce qu'on en fasse mention dans les articles ? Vous jouez avec les mots et vous moquez du monde. Il m'apparaît de plus en plus évident que vous n'êtes pas ici pour contribuer positivement, mais pour vous ériger en censeur. Vous cherchez à provoquer l'exaspération de vos interlocuteurs pour pouvoir éliminer facilement leurs remarques : cf. votre échange avec Dhegiha ci-dessus. Je pers mon temps à chercher à vous répondre de façon constructive. La suite se passera au salon de médiation. Aucassin (discuter) 4 novembre 2014 à 14:54 (CET)
- « Vous pensez réellement que le contenu d'une norme se résume en un titre ? » → Homme de paille. Je n'ai pas écrit que « le contenu d'une norme se résume en un titre ».
- « Vous pensez réellement [...] Qu'un simple code justifierait d'un article séparé, alors que vous savez très bien [...] qu'ils ne seraient vraisemblablement, et à bon droit, pas jugés admissibles en tant qu'articles ? » → J'ai écrit ci-dessus que « il est possible (Wikipédia:N'hésitez pas !) de créer des articles sur des codes de langues. ISO 639:nor et ISO 639:zho existent déjà. » J'ajoute que ISO 639:nor (d · h · j · ↵) et ISO 639:zho (d · h · j · ↵) ont été créés le 29 mai 2007, et n'ont depuis jamais fait l'objet de demande d'admissibilité ou de suppression. Vous avez écrit une connerie.
- « Alors même que vous n'avez de cesse que de vous opposer à ce qu'on en fasse mention dans les articles » → Vous êtes en train de dire que si je m'oppose à la présence de détails sur des codes de langue dans les articles consacrés aux langues, alors je m'oppose à la présence de détails sur des codes de langue dans les articles consacrés aux codes de langues. C'est faux, c'est illogique et c'est une connerie.
- « Vous jouez avec les mots et vous moquez du monde. » → Accusations infondées et attaques personnelles.
- « Vous cherchez à provoquer l'exaspération de vos interlocuteurs pour pouvoir éliminer facilement leurs remarques : cf. votre échange avec Dhegiha ci-dessus. » → Mauvais résumé de mon échange avec Dhegiha. Meilleur : Dhegiha m'a accusé de dénigrer; je lui ai donné l'occasion de s'expliquer; il a rejeté cette occasion.
- « Je pers mon temps à chercher à vous répondre de façon constructive. » → Ce n'est pas cete phrase qui va m'empécher de vous répondre ici.
- Visite fortuitement prolongée (discuter) 4 novembre 2014 à 22:15 (CET)
- Vous pensez réellement que le contenu d'une norme se résume en un titre ? Qu'un simple code justifierait d'un article séparé, alors que vous savez très bien qu'ils n'ont d'intérêt que vis-à-vis de la langue en question dans son contexte, qu'ils ne seraient vraisemblablement, et à bon droit, pas jugés admissibles en tant qu'articles ? Alors même que vous n'avez de cesse que de vous opposer à ce qu'on en fasse mention dans les articles ? Vous jouez avec les mots et vous moquez du monde. Il m'apparaît de plus en plus évident que vous n'êtes pas ici pour contribuer positivement, mais pour vous ériger en censeur. Vous cherchez à provoquer l'exaspération de vos interlocuteurs pour pouvoir éliminer facilement leurs remarques : cf. votre échange avec Dhegiha ci-dessus. Je pers mon temps à chercher à vous répondre de façon constructive. La suite se passera au salon de médiation. Aucassin (discuter) 4 novembre 2014 à 14:54 (CET)
Autres codes modifier
Je vois que la Wikipédia en langue anglaise mentionne entre autres également trois autres sources de codes notables dans son modèle d'infobox (https://en.wikipedia.org/wiki/Template:Infobox_language) : The Linguist List (http://linguistlist.org) et Glottolog (http://glottolog.org) : je ne vois pas de discussion sur la pertinence d'ajouter ou pas ces sources à l'infobox française : un avis ? --Loup Solitaire (discuter) 20 février 2015 à 12:15 (CET)
Affichage des codes ISO 639-3, de leur type et de leur étendue modifier
![]() SyntaxTerror : Bizarre, bizarre : sous Windows 10, le champ ISO 639-3 apparaît avec certains navigateurs mis en un double gras qui attire très fortement l'attention dessus sans raison particulière. Je l'ai constaté avec Firefox (dont ce n'est pas le seul problème de compatibilité avec Windows 10 pour l'affichage de Wikipédia) et Explorer ; en revanche, pas de problème avec Chrome et Edge. Problème d'interprétation du Lua ? Par ailleurs, la traduction des attributs du code ("type" et "étendue") n'est pas toujours homogène : on peut avoir par ex. individuel, individuelle, langue individuelle... Les valeurs possibles sont données en documentation, mais je l'avais ajoutée très longtemps après que le champ ne soit créé ; peut-être faudrait-il passer un bot pour harmoniser. Mais il faudrait faire la liste de toutes les variations avant de les renvoyer vers les formulations conventionnelles appropriées ! Aucassin (discuter) 21 octobre 2015 à 10:27 (CEST)
SyntaxTerror : Bizarre, bizarre : sous Windows 10, le champ ISO 639-3 apparaît avec certains navigateurs mis en un double gras qui attire très fortement l'attention dessus sans raison particulière. Je l'ai constaté avec Firefox (dont ce n'est pas le seul problème de compatibilité avec Windows 10 pour l'affichage de Wikipédia) et Explorer ; en revanche, pas de problème avec Chrome et Edge. Problème d'interprétation du Lua ? Par ailleurs, la traduction des attributs du code ("type" et "étendue") n'est pas toujours homogène : on peut avoir par ex. individuel, individuelle, langue individuelle... Les valeurs possibles sont données en documentation, mais je l'avais ajoutée très longtemps après que le champ ne soit créé ; peut-être faudrait-il passer un bot pour harmoniser. Mais il faudrait faire la liste de toutes les variations avant de les renvoyer vers les formulations conventionnelles appropriées ! Aucassin (discuter) 21 octobre 2015 à 10:27 (CEST)
- Aucassin : le code n'est pas en lua mais en wikicode, j'ai éventré les modèles {{Lien ISO 639-3}} et {{Infobox/Ligne mixte optionnelle}} car ils rentraient en conflit avec le <span style=plainlinks> que j'ai utilisé pour ne laisser qu'un seul icone d'indication de lien externe en fin de ligne (qui est un bidouillage : ce n'est qu'une image en fait). Je vais regarder si le problème se pose aussi avec windows 7 et essayer de le régler, sinon je reviendrai à la version avec tous les icônes. C'est un problème de balises HTML et sans elles il y a un problème d'interligne légèrement plus grand qui se pose, et j'ai juste tripatouillé jusqu'à ce que ça marche sans vraiment comprendre leur fonctionnement. Je vais régler le problème si je peux le voir, sinon je laisserait mon ancienne version avec plein d'icônes de lien externe et je demanderai au projets infobox et modèle, mais comme tu le sais, ils ne sont pas très réactifs...
- Concernant les valeurs des paramètres type et étendue, je ne pense pas que ce soit très important qu'ils soient tous identiques, par contre je suis revenu sur leur oblitération par VFP car ils aident à mieux comprendre ce que signifient les codes ISO 639-3. Cordialement, Şÿℵדαχ₮ɘɼɾ๏ʁ You talkin' to me? 21 octobre 2015 à 13:20 (CEST)
- Voilà c'est réglé. En fait, en bidouillant le modèle, j'avais mis le lien ISO 639-3 en gras dans une de mes versions, puis je n'avais pas enlevé ce gras dans les suivantes, et des navigateurs intelligents comme chrome détectent que le texte est déjà supposé être en gras et le laissent en gras simple tandis que d'autres le mettent deux fois en gras. Meric de la remarque et dis-moi si tu vois encore des problèmes, moi j'utilise Comodo Dragon et SRWare Iron comme navigateurs et je n'ai pas souvent de problèmes d'affichage. Şÿℵדαχ₮ɘɼɾ๏ʁ You talkin' to me? 21 octobre 2015 à 13:36 (CEST)
- En passant, les contenus de ces paramètres sont ici : type et étendue mais ce sont des listes brutes et je ne sais pas trop comment différencier les valeurs automatiquement. Şÿℵדαχ₮ɘɼɾ๏ʁ You talkin' to me? 22 octobre 2015 à 00:04 (CEST)
Je ne connaissais pas cette fonction, c'est super pour préparer un nettoyage des données. En triant par tableur, j'ai abouti aux jeux de données des champs type et étendue. En dehors de quelques aberrations que je viens de corriger, voici comment harmoniser par rapport aux indications de la documentation.
Pour le paramètre « type », sont à harmoniser sur :
- vivante : langue vivante ~ langues vivante ~ vivant ~ vivante
- éteinte : éteint ~ éteinte ~ Éteinte ~ langue éteinte ~ langue morte ~ morte
- ancienne : ancienne ~ langue ancienne
- historique : historique ~ langue historique
- construite : construite ~ langue imaginaire
Pour le paramètre « étendue », sont à harmoniser sur :
- individuelle : individuelle ~ langue individuelle ~ lngue individuelle
- collective : collectif ~ collective
- macrolangue : [[macro-langue ~ [[macro-langue]] ~ macrolangue ~ macro-langue (L'une ou l'autre des orthographes se trouvent. Le renvoi vers l'article macro-langue est sans doute pertinent pour le lecteur mais posera des problèmes pour l'exploitation automatique des données des infobox.)
- dialecte : n'a pas été utilisé jusqu'à maintenant
- enfin, il y a un certain nombre de données « groupe » qui correspondent principalement à macrolangue mais avec quelques cas où le renvoi doit plutôt se faire sur collective. Un tri manuel est donc nécessaire avant d'envisager un remplacement automatique.
Aucassin (discuter) 22 octobre 2015 à 18:15 (CEST)
- Aucassin : moi si tu est sur de toutes les syntaxes, j'y passe un coup d'AWB et ça sera fait, je n'aurais rien a contrôler quasiment.
- Je pense que mettre des liens internes serait une bonne chose. Concernant le texte, mettre « langue » à chaque fois me semble un peu gênant, mais c'est peut-être plus clair. Après, faire les modifications avant ou après le passage d'un bot c'est égal, avec une liste spécifique des articles à modifiés, je peux facilement remplacer tous les « macrolangue » voulus par des « collective ».
- Sinon, c'est une bonne idée le tri avec un tableur, je n'y avait pas pensé.Şÿℵדαχ₮ɘɼɾ๏ʁ You talkin' to me? 22 octobre 2015 à 19:17 (CEST)
- SyntaxTerror :Pour moi, à part "groupe" qui est à faire à la main, on peut y aller. Je pense que mieux vaut éviter les liens finalement : 1) neuf utilisateurs sur dix oublieront de les faire 2) seul celui sur macrolangue envoie vers un article spécifique sur l'acception retenue par le SIL. Je vais plutôt faire des liens du titre du champ vers les pages explicatives du SIL qui précisent le sens des annotations des codes. Aucassin (discuter) 24 octobre 2015 à 09:17 (CEST)
- Aucassin : Je vais faire les deux champs en même temps, c'est quasiment égal en termes de temps de travail et ça facilitera les choses pour la suite. Après, si j'ai des listes des noms d'articles avec la valeur correcte du paramètre groupe à mettre, je pourrais aussi faire les modifs rapidement (par contre je ne suis pas capable de décider quelle valeur mettre à quelle langue).
- Les valeurs que je propose de mettre sont celles en italique dans tes listes ci-dessus (mettre « langue » à chaque fois ne me dit plus trop en fait). Je n'attends que ton accord pour commencer. Cordialement, Şÿℵדαχ₮ɘɼɾ๏ʁ You talkin' to me? 24 octobre 2015 à 10:42 (CEST)
- J'ai bossé aujourd'hui sur la traduction des pages de SIL que tu mets en lien pour type et étendue, pour remplacer les liens externes que tu as mis à ces paramètres dans l'infobox Langue. Ça m'a fait comprendre plusieurs choses à propos de l'étendue : avec le code 639-3, il n'y a que des langues individuelles et les macro-langues. Les dialectes sont considérés comme des langues individuelles et les langues collectives, ou plutôt les collections de langues ne sont reconnues que par les codes 639-2/639-5 (voir [3]), donc le remplissage de ce paramètre est simple : soit un code est attribué à une macro-langue (il y en a 62, j'ai mis à jour le tableau de l'artice Macro-langue, soit c'est une langue individuelle.
- Je pense revoir la disposition des paramètres iso3 pour faire plus comme la version anglaise : ça permettra de voir plus rapidement quel est le code générique et les noms des langues filles des macro-langues (comme ici : en:Bontok language). Comme c'est limité à 62 langues, ça ne représenta pas beaucoup de travail. Par contre, pour certaines macro-langues, il va y en avoir pas mal (zapotèque : 57, quechua : 44, etc.), je vais donc voir si je peux mettre une liste déroulante quand il y a plus de 10 langues filles. Cordialement, Şÿℵדαχ₮ɘɼɾ๏ʁ You talkin' to me? 24 octobre 2015 à 22:16 (CEST)
- Ok avec toutes ces propositions, et merci pour les compléments dans ISO 639-3 : c'est effectivement mieux de faire des liens internes, en français. Je partage l'avis qu'il vaut mieux ne pas s'encombrer de langue dans la formulation chaque annotation, c'est contextuellement évident et ne ferait que surcharger la formulation. Pour les données typées groupe, il « suffit » d'aller récupérer la donnée correcte dans la section ISO-639 du site du SIL ; le nombre n'en est heureusement pas considérable.
- Pour l'ajout des codes spécifiques des langues incluses dans les macrolangues : puisque nous acceptons ailleurs les codes multiples, pourquoi pas ? C'est une bonne idée que de les mettre en liste déroulante (nous le faisons déjà pour les longues listes de pays, cf. par ex. français), je serais même porté à le faire systématiquement en les mettant dans une liste légendée « langues incluses » dans la section permettant d'annoter les codes ISO 639-3. Je crois que ce serait une présentation plus claire pour le lecteur que de séparer ainsi bien clairement les deux niveaux de données : immédiatement en premier lieu, le code correspondant exactement à la macrolangue décrite dans l'article, et en second lieu la liste des variétés incluses, si le lecteur désire aller plus loin en ouvrant la liste déroulante.
- Merci globalement de faire ainsi avancer ce chantier
 Aucassin (discuter) 25 octobre 2015 à 09:34 (CET)
Aucassin (discuter) 25 octobre 2015 à 09:34 (CET)
- Aucassin : je vais faire comme j'ai dit alors. Je suis également d'accord pour une liste déroulante pour toutes les macro-langues, ça sera plus clair pour le lecteur. Ma modif de l'infobox risque de faire un peu de bordel dans les articles en attendant qu'ils soient modifiés, donc je vais d'abord revenir à la version avec un seul code iso3, je ferai ensuite les modifications sur les articles, puis je mettrai en place la nouvelle version de l'infobox. Cordialement, Şÿℵדαχ₮ɘɼɾ๏ʁ You talkin' to me? 25 octobre 2015 à 10:47 (CET)
- Il y a un petit problème : certaines langues (ou groupes de langues, ou groupes de dialectes, dur à dire...) comme le sahaptin ont plusieurs codes mais un seul article et ne sont pas des macro-langues. Je vais donc faire une liste déroulante pour les macro-langues (j'ai réussi à bidouiller un truc en prenant en exemple le modèle en anglais) et une simple liste pour ces cas. Şÿℵדαχ₮ɘɼɾ๏ʁ You talkin' to me? 26 octobre 2015 à 10:01 (CET)
Affichage de l'infobox pour le jersiais modifier
Bonjour, comme vous le constaterez en consultant jersiais (sinon je m'inquiète pour ma santé mentale), plusieurs lignes « blanches » sont placées en début d'article. Elles disparaissent lorsqu'on ne renseigne pas le code iso-3. Je n'ai pas compris pourquoi. J'ai vu qu'il y avait eu des modif du modèle en octobre. Si quelqu'un de compétent veut bien se pencher sur le sujet...--Rehtse (échanger) 20 novembre 2015 à 18:32 (CET)
- Bonjour Rehtse
 c'est moi qui ai fait ces modifs, et ce dont tu parles est très étrange (mais apparemment vrai), par contre je ne vois pas d'où ça peut venir. C'est la première fois que je vois ça et je n'ai aucune explication pour ça, c'est vraiment illogique... Jusqu'au moment où on aura trouvé la logique de la chose ! Je vais regarder un peu et si je n'arrive à rien, il faudrait demander demain sur le Bistro, il y aura sans doute plus de réponses qu'ici. Cordialement, Şÿℵדαχ₮ɘɼɾ๏ʁ You talkin' to me? 20 novembre 2015 à 19:55 (CET)
c'est moi qui ai fait ces modifs, et ce dont tu parles est très étrange (mais apparemment vrai), par contre je ne vois pas d'où ça peut venir. C'est la première fois que je vois ça et je n'ai aucune explication pour ça, c'est vraiment illogique... Jusqu'au moment où on aura trouvé la logique de la chose ! Je vais regarder un peu et si je n'arrive à rien, il faudrait demander demain sur le Bistro, il y aura sans doute plus de réponses qu'ici. Cordialement, Şÿℵדαχ₮ɘɼɾ๏ʁ You talkin' to me? 20 novembre 2015 à 19:55 (CET)
- Bravo, t'as trouvé, et en plus ça a résolu un autre problème. Je ne comprends pas le lien entre tout ça, mais maintenant, ça marche.--Rehtse (échanger) 20 novembre 2015 à 20:21 (CET)
- Rehtse : voilà, ça semble réglé. J'avais laissé du code tout pourri (un bricolage maison) que j'ai remplacé par une adaptation de l'ancien code. À priori ça à l'air de marcher. Merci pour la remarque, car sur la majorité des articles comprenant cette infobox il n'y avait pas de problème. le même truc se produisait avec Normand, avec un espace moins grand. Je ne saurais vraiment pas dire pourquoi... Şÿℵדαχ₮ɘɼɾ๏ʁ You talkin' to me? 20 novembre 2015 à 20:35 (CET)
- SyntaxTerror : Ah, ben je t'avais remercié juste au-dessus. Tu as résolu deux problèmes d'un coup...--Rehtse (échanger) 20 novembre 2015 à 20:37 (CET)
- Bravo, t'as trouvé, et en plus ça a résolu un autre problème. Je ne comprends pas le lien entre tout ça, mais maintenant, ça marche.--Rehtse (échanger) 20 novembre 2015 à 20:21 (CET)
Affichage d'une image modifier
Bonjour !
Dans la cousine anglophone de cette infobox, il est possible de rajouter une image en tête de gondole (regardez par exemple dans l'article Volapük). Ce n'est malheureusement pas possible en français. Est-il possible de changer cela ? Ce serait utile pour presque toutes les langues construites (et en tout cas toutes les LAIs) et, je pense, pour certaines langues naturelles (par exemple, pourquoi ne pas mettre le drapeau de la francophonie sur l'article français ?).
Qu'en pensez-vous ?
— Ἐμμανουήλ [@] -- [✉] 22 février 2016 à 13:42 (CET)
- Theomanou : c'est bien sur possible et faisable en deux minutes, mais je ne vois pas bien l'intérêt de la chose. Comme je l'ai dit sur le bistro, je ne vois pas vraiment comment une image peut représenter une langue et de toute façon, une image peut aussi bien être mise dans une vignette. J'aimerais plus d'avis avant de faire la modification, il faudrait peut-être mettre un message sur le café des linguistes. Cordialement, Şÿℵדαχ₮ɘɼɾ๏ʁ 22 février 2016 à 14:09 (CET)
- Merci pour ta rapide réponse SyntaxTerror, aussi bien ici que sur le bistro ! Certaines langues ont un symbole qui les représente (par exemple le français ou les LAIs, comme je l'ai dit dans le premier message). Mais même si cela ne représente qu'une toute petite minorité, rien n'empêche de laisser cette option vide dans la grande majorité des cas où elle est inutile. Si en plus la modification est facile à faire, je ne vois vraiment pas pourquoi ne pas l'ajouter, puisqu'elle ne gênera l'affichage d'aucune page où elle sera absente.
- — Ἐμμανουήλ [@] -- [✉] 22 février 2016 à 14:23 (CET)
- Theomanou : on peut bien sûr ajouter plein de paramètres aux infoboxes, mais habituellement on en discute avant, notamment les projet concernés, pour avoir d'autres avis et éventuellement découvrir des choses auxquelles on n'aurait pas pensé. Attendons une dizaine de jours pour avoir plus d'avis. Şÿℵדαχ₮ɘɼɾ๏ʁ 22 février 2016 à 14:33 (CET)
- SyntaxTerror : bien entendu, je n'attendais pas une implémentation dans la journée (mieux vaut bien que vite), et il est tout à fait normal de laisser ceux qui connaissent bien mieux et le fonctionnement d'une infobox et les conditions de son utilisation en discuter. Je me contentais de bien présenter ma petite argumentation, histoire de faciliter les débats ensuite.
Je vais transmettre sur le café de linguistes.(trop tard et merci !) - — Ἐμμανουήλ [@] -- [✉] 22 février 2016 à 14:38 (CET)
- Theomanou et Hautbois : Je viens d'ajouter les paramètres pour mettre une image en haut de l'infobox Langue. Lire la documentation du modèle pour savoir quels paramètres ajouter.
- Je ne suis pas vraiment pour l'ajout de ces paramètres, mais comme je les ai ajoutés quand même vu la demande. On verra pas la suite si ça pose des problèmes. Comme les paramètres ne sont pas dans les articles, les contributeurs occasionnels ne seront pas tentés d'y mettre n'importe quoi. Cordialement, Şÿℵדαχ₮ɘɼɾ๏ʁ 29 février 2016 à 19:36 (CET)
- Merci beaucoup Şÿℵדαχ₮ɘɼɾ๏ʁ ! Je trouve que cette solution (mettre en place et supprimer si ça pose problème) est une bonne solution. — Ἐμμανουήλ [@] -- [✉] 29 février 2016 à 19:49 (CET)
- SyntaxTerror :
 Merci
Merci  cf. Volapük
cf. Volapük  — Hautbois [canqueter] 29 février 2016 à 19:59 (CET)
— Hautbois [canqueter] 29 février 2016 à 19:59 (CET)
- Merci beaucoup Şÿℵדαχ₮ɘɼɾ๏ʁ
Bandeau supérieur modifier
![]() Projet:Modèle - Projet:Infobox. Il y a un petit logo dans le bandeau fort sympathique. Cependant le texte dans le bandeau ne passe pas sur ce logo. On se retrouve ainsi avec des bandeaux parfois très larges, voir par exemple Francoprovençal. Ce n'est par contre pas le cas pour Modèle:Infobox Association (qui est une infobox de type V3 alors que Modèle:Infobox Langue est de type V2), exemple : Internet Corporation for Assigned Names and Numbers. Pourrait-on modifier cela ? — Berdea (discuter) 17 août 2020 à 01:40 (CEST)
Projet:Modèle - Projet:Infobox. Il y a un petit logo dans le bandeau fort sympathique. Cependant le texte dans le bandeau ne passe pas sur ce logo. On se retrouve ainsi avec des bandeaux parfois très larges, voir par exemple Francoprovençal. Ce n'est par contre pas le cas pour Modèle:Infobox Association (qui est une infobox de type V3 alors que Modèle:Infobox Langue est de type V2), exemple : Internet Corporation for Assigned Names and Numbers. Pourrait-on modifier cela ? — Berdea (discuter) 17 août 2020 à 01:40 (CEST)
- Bonsoir Berdea
 . Puisque tu notifies le projet Infobox, voici une réponse qui avait été faite là-bas : Discussion Projet:Infobox/Archive 2019#Pleine largeur des titres infobox. --FDo64 (discuter) 17 août 2020 à 23:45 (CEST)
. Puisque tu notifies le projet Infobox, voici une réponse qui avait été faite là-bas : Discussion Projet:Infobox/Archive 2019#Pleine largeur des titres infobox. --FDo64 (discuter) 17 août 2020 à 23:45 (CEST)
Ajout d'une ligne Atlas of Pidgin and Creole Language Structures modifier
Bonjour
Je viens de plus ou moins découvrir l'Atlas des structures des langues pidgin et créoles (APiCS) et son site web, très bien fait et vraiment très complet qui traite des pidgins et des créoles, et qui en plus est entièrement sous licence Creative Commons Attribution (on peut donc piquer dedans comme on veut, il suffit de citer).
Je crois qu'il serait très intéressant d'indiquer les liens vers les études faites sur ce site dans les infobox, un peu comme on le fait déjà pour le SIL, Glottolog, le WALS, etc. Ça ne concerne que 76 langues (je ne suis pas sûr qu'on ait un article pour chacune), mais les informations trouvées là-bas sont de toute première qualité (voir par exemple l'étude de l'afrikaans). Ce nombre n'est pas censé changer, car il dépend de l'édition papier de l'atlas.
Je pense faire une section spéciale (certainement entre celle des codes de langues et l'échantillon) et je passerai ensuite ajouter le paramètre dans les articles.
Je compte faire aussi un modèle similaire à {{Ethnologue}} pour la section liens externes, dont on pourra se servir pour les citations éventuelles.
Cordialement, Şÿℵדαχ₮ɘɼɾ๏ʁ 14 juillet 2022 à 23:12 (CEST)
Ajout paramètre alt carte modifier
Je pense ajouter le paramètre alt carte en complément de légende carte plutôt qu'utiliser la légende aussi pour le alt parce que la légende contient souvent des modèles {{Légende}} ou des indications de couleurs qui sont peu utiles si la carte n'est pas visible. Des objections ? mat.duf (discuter) 30 septembre 2022 à 17:18 (CEST)
- @mat.duf : je vois mal comment fournir une alternative textuelle à une carte, surtout si l'on doit s'en tenir à 120 caractères. Peux-tu donner un exemple ? Cordialement, Şÿℵדαχ₮ɘɼɾ๏ʁ 30 septembre 2022 à 18:00 (CEST)
- SyntaxTerror : Un exemple à partir de Afrikaans :
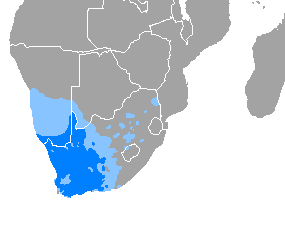
[[Fichier:Idioma afrikáans.png|Répartition géographique de l'afrikaans en Afrique australe (bleu : majoritaire ; bleu ciel : minoritaire)|alt=Carte de la répartition de l'afrikaans, majoritaire à l'ouest de l'Afrique du Sud jusqu'à Port Elizabeth et en Namibie.]]- (122 caractères). Je ne suis pas un expert en rédaction ou en accessibilité mais je pense que c'est mieux qu'un alt qui parle de bleu et bleu ciel.
- Une autre solution serait d'enlever aussi l'utilisation de
légende cartepour le alt et utiliser par défaut un alt du genreCarte de répartition géographique de la langue, mais à ce niveau là ça ne coûte pas grand chose d'ajouter un paramètre pour personnaliser le alt. mat.duf (discuter) 30 septembre 2022 à 19:13 (CEST)- @mat.duf : franchement je ne suis pas sûr de l'utilité de la chose. C'est sûr qu'il faut rendre le plus de choses accessibles que possible, mais dans certains cas ça ne l'est pas. Ici c'est un exemple relativement simple, mais je ne sait pas si ça peut aider une personne aveugle par exemple à se rendre compte de la situation (je suis plutôt bon en géographie, mais n'ai aucune idée d'où est Port Elizabeth, et je pense qu'une majorité ne sait pas où est la Namibie, mais bon).
- Certaines cartes que j'ai faites sont beaucoup plus complexes que ça ([4], [5]), avec des pays bien moins connus, et je ne pense pas qu'on puisse les décrire avec un court texte, surtout quand on peut le faire dans le détail dans le corps de l'article.
- Il faudrait parler de cette discussion sur le projet:Langues et l'WP:Atelier accessibilité, mais je sais par expérience que le sujet des alternatives textuelles n'intéresse malheureusement pas grand monde.
- Sinon, deux choses plus ou moins liées mais ne concernant pas le sujet :
- Cette carte est fausse (j'en parle plus en détail sur Discussion:Afrikaans#Problème avec les cartes).
- Pour notifier, il faut le faire en même temps qu'on signe son message, sinon ça ne marche pas (je n'ai pas été notifié cette fois ci).
- Cordialement, Şÿℵדαχ₮ɘɼɾ๏ʁ 30 septembre 2022 à 22:19 (CEST)
- SyntaxTerror :
- Pour qu'on se comprenne bien, j'ai proposé cette solution parce que je pense que la solution actuelle est néfaste et qu'il faut changer les valeurs mises dans les alt. Les légendes des cartes contiennent très souvent des indications de couleur et assez souvent du wikicode (alors que le alt doit être du plaintext) qui vont troubler la lecture si l'image n'est pas visible.
- Pour résoudre ça la solution la plus simple est d'imposer un alt par défaut suffisamment générique pour décrire la majorité des cas.
- Mais derrière, j'imaginais qu'il pouvait y avoir des cas dans lesquels on aurait voulu personnaliser le alt pour qu'il soit plus précis, et donc d'avoir un paramètre dédié.
- Si vous pensez que c'est inutile, d'avoir un paramètre dédié, je peux prendre la solution la plus simple et d'imposer le alt par défaut qui existe déjà sans utiliser la valeur de la légende pour le alt. mat.duf (discuter) 2 octobre 2022 à 12:36 (CEST)
- @mat.duf : qu'est ce qui te fait dire que « la solution actuelle est néfaste » ? Ajouter un alt ne va pas empêcher un lecteur d'écran de lire la légende, et le wikicode ne pose pas plus de problème dans cette légende qu'ailleurs sur la page.
- Avant de vouloir implémenter ça et être sûrs de ne pas faire de bêtise parce qu'on aurait omis quelque chose, il faudrait avoir plus d'avis, en en parlant sur le projet:Langues et l'WP:Atelier accessibilité comme suggéré plus haut (dois-je le faire à ta place ?), et si on pouvait avoir l'avis de quelqu'un qui se sert affectivement de ces alts car il utilise un lecteur d'écran, ça serait constructif (mais même s'il en existe forcément, je n'ai jamais entendu parler d'une telle personne).
- Cordialement, Şÿℵדαχ₮ɘɼɾ๏ʁ 2 octobre 2022 à 17:17 (CEST)
- Merci SyntaxTerror pour ces réponses, après avoir réétudié le problème je me suis rendu compte que certains problèmes que j'avais vu sont effectivement moins graves que ce que je pensais (notamment le alt est plus nettoyé que le title) et que la solution que je propose risque de poser plus de problèmes que d'en résoudre. Je pense toujours que c'est pas forcément une bonne idée de forcer le alt à la même valeur que le title (parce que sinon ça serait les mêmes valeurs en HTML) mais pour l'instant je pense qu'il faut réfléchir à une autre solution. mat.duf (discuter) 13 octobre 2022 à 13:58 (CEST)
- SyntaxTerror, Mat.duf : La solution était incorrecte car elle générait en tant que paramètre alt des éléments qui n'avaient rien à y faire, causant notamment des erreurs de Lint. Recopier la légende en tant que paramètre alt étant inutile, et le modèle {{Infobox/Image}} gérant correctement cette absence à partir de la légende, j'ai simplement supprimé la recopie de la légende en tant que paramètre alt. En effet, dans ce cas, il me semble effectivement inutile de permettre de mettre une description alternative à une carte, car il n'est pas possible de décrire celle-ci de manière abstraite.
- Wikipédiennement, Epok__ (✉), le 8 novembre 2022 à 07:04 (CET)
- Merci SyntaxTerror

![[4]](https://commons.wikimedia.org/wiki/File:Yanomaman.svg){kind=link}
![[5]](https://commons.wikimedia.org/wiki/File:Wolof,_gambian_wolof.svg){kind=link}