Auto-encodeur variationnel
En apprentissage automatique, un auto-encodeur variationnel (ou VAE de l'anglais variational auto encoder)[1], est une architecture de réseau de neurones artificiels introduite en 2013 par D. Kingma et M. Welling, appartenant aux familles des modèles graphiques probabilistes et des méthodes bayésiennes variationnelles.
Les VAE sont souvent rapprochés des autoencodeurs[2],[3] en raison de leur architectures similaires. Leur utilisation et leur formulation mathématiques sont cependant différentes.
Les auto-encodeurs variationnels permettent de formuler un problème d'inférence statistique (par exemple, déduire la valeur d'une variable aléatoire à partir d'une autre variable aléatoire) en un problème d'optimisation statistique (c'est-à-dire trouver les valeurs de paramètres qui minimisent une fonction objectif)[4]. Ils représentent une fonction associant à une valeur d'entrée une distribution latente multivariée, qui n'est pas directement observée mais déduite depuis un modèle mathématique à partir de la distribution d'autres variables. Bien que ce type de modèle ait été initialement conçu pour l'apprentissage non supervisé[5], son efficacité a été prouvée pour l'apprentissage semi-supervisé[6],[7] et l'apprentissage supervisé[8].
Architecture modifier
Dans un VAE, les données d'entrée sont échantillonnées à partir d'une distribution paramétrée (la distribution a priori, en termes d'inférence bayésienne), et l'encodeur et le décodeur sont entraînés conjointement de sorte que la sortie minimise une erreur de reconstruction dans le sens de la divergence de Kullback-Leibler entre la distribution paramétrique postérieure et la vraie distribution a posteriori[9],[10].
Formulation modifier



On note le vecteur contenant l'ensemble des variables observées que l'on souhaite modéliser. Ce vecteur est une variable aléatoire, caractérisé par une distribution de probabilité inconnue , que l'on souhaite approximer par une distribution paramétrée ayant pour paramètres .



On introduit alors un vecteur aléatoire distribué conjointement avec (c'est-à-dire dont la loi de probabilité n'est pas indépendante de celle de ). Ce vecteur représente un encodage latent de , que l'on ne peut observer directement.

On exprime alors la distribution via la loi de probablitié marginale sur , ce qui donne alors:

où représente la distribution conjointe sous des données observables et de leur représentation latente . Selon la formule des probabilités composées, l'équation peut être réécrite comme


Dans l'auto-encodeur variationnel classique, on fait l'hypothèse que est un vecteur à valeur réelles de dimension finie, et suit une loi normale. Par conséquent, est un mélange de distributions gaussiennes.


On peut voir les relations entre les données d'entrée et leur représentation latente comme un problème d'inférence bayésienne avec
- représente la distribution probabilité a priori dans l'espace latent
- représente la vraisemblance
- représente la distribution de probabilité a posteriori



Malheureusement, le calcul de est au mieux coûteux, et dans la plupart des cas, impossible. Pour résoudre ce problème, il est nécessaire d'introduire une autre fonction pour approximer la distribution a posteriori :


où est l'ensemble des paramètres de .


Ainsi le problème est formulé pour pouvoir être appliqué dans une architecture de réseau de neurones auto-encodeur, dans lequel la distribution de vraisemblance conditionnelle est représentée par un décodeur probabiliste, tandis que la distribution a posteriori approchée est représentée par un codeur probabiliste. La mise en œuvre d'un VAE consistera donc à calculer les valeurs optimales des paramètres et par un apprentissage automatique.

Fonction de perte ELBO modifier
Comme dans tout problème d'apprentissage profond, il est nécessaire de définir une fonction de perte différentiable afin de mettre à jour les poids du réseau par rétropropagation lors de l'apprentissage.
Pour les auto-encodeurs variationnels, l'idée est de minimiser conjointement les paramètres du modèle génératif pour réduire l'erreur de reconstruction entre l'entrée et la sortie, et pour avoir , la distribution postérieure approchée, le plus près possible de , la vraie distribution de probabilité a posteriori.

Comme fonction de coût pour la reconstruction, l'erreur quadratique moyenne et l'entropie croisée sont souvent utilisées.
Pour la fonction de coût de distance entre les deux distributions, la divergence inverse de Kullback – Leibler est un bon choix pour pousser en dessous de [1],[11].

Reparamétrisation modifier


Pour rendre la formulation ELBO adaptée à des fins d'apprentissage, il est nécessaire de modifier légèrement la formulation du problème et la structure du VAE[12].
L'échantillonnage stochastique est l'opération non différentiable par laquelle il est possible d'échantillonner à partir de l'espace latent et d'alimenter le décodeur probabiliste.
L'hypothèse principale sur l'espace latent est qu'il peut être considéré comme un ensemble de distributions gaussiennes multivariées, et peut donc être décrit comme
- .
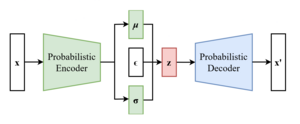
Le schéma d'un auto-encodeur variationnel après l'astuce de reparamétrisation.


Etant donné et défini comme le produit élément par élément, l'astuce de reparamétrisation modifie l'équation ci-dessus comme



Grâce à cette transformation (qui peut être étendue à des distributions non gaussiennes), le VAE devient entraînable et le codeur probabiliste doit apprendre à mapper une représentation compressée de l'entrée dans les deux vecteurs latents et , tandis que la stochasticité reste exclue du processus de mise à jour et est injectée dans l'espace latent en tant qu'entrée externe via le vecteur aléatoire .



Références modifier
- Diederik P. Kingma et Max Welling, « Auto-Encoding Variational Bayes », arXiv:1312.6114 [cs, stat], (lire en ligne, consulté le )
- (en) Kramer, « Nonlinear principal component analysis using autoassociative neural networks », AIChE Journal, vol. 37, no 2, , p. 233–243 (DOI 10.1002/aic.690370209, lire en ligne)
- (en) Hinton et Salakhutdinov, « Reducing the Dimensionality of Data with Neural Networks », Science, vol. 313, no 5786, , p. 504–507 (PMID 16873662, DOI 10.1126/science.1127647, Bibcode 2006Sci...313..504H, S2CID 1658773, lire en ligne)
- (en) « A Beginner's Guide to Variational Methods: Mean-Field Approximation », Eric Jang,
- Wei-Ning Hsu, Yu Zhang et James Glass, 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), , 16–23 p. (ISBN 978-1-5090-4788-8, DOI 10.1109/ASRU.2017.8268911, arXiv 1707.06265, S2CID 22681625), « Unsupervised domain adaptation for robust speech recognition via variational autoencoder-based data augmentation »
- M. Ehsan Abbasnejad, Anthony Dick et Anton van den Hengel, Infinite Variational Autoencoder for Semi-Supervised Learning, , 5888–5897 p. (lire en ligne)
- (en) Xu, Sun, Deng et Tan, « Variational Autoencoder for Semi-Supervised Text Classification », Proceedings of the AAAI Conference on Artificial Intelligence, vol. 31, no 1, (lire en ligne)
- Kameoka, Li, Inoue et Makino, « Supervised Determined Source Separation with Multichannel Variational Autoencoder », Neural Computation, vol. 31, no 9, , p. 1891–1914 (PMID 31335290, DOI 10.1162/neco_a_01217, S2CID 198168155, lire en ligne)
- An, J., & Cho, S. (2015). Variational autoencoder based anomaly detection using reconstruction probability. Special Lecture on IE, 2(1).
- Kingma et Welling, « An Introduction to Variational Autoencoders », Foundations and Trends in Machine Learning, vol. 12, no 4, , p. 307–392 (ISSN 1935-8237, DOI 10.1561/2200000056, arXiv 1906.02691, S2CID 174802445)
- (en) « From Autoencoder to Beta-VAE », Lil'Log,
- Bengio, Courville et Vincent, « Representation Learning: A Review and New Perspectives », IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no 8, , p. 1798–1828 (ISSN 1939-3539, PMID 23787338, DOI 10.1109/TPAMI.2013.50, arXiv 1206.5538, S2CID 393948, lire en ligne)