Discussion utilisateur:Vincent Ramos/Archives6
Roby : Cher Vincent, je partage ton avis en ce qui concerne la préservation de la mémoire et donc la nécessité, lors d'une destruction, de prendre des avis compétents et de ne pas agir d'autorité. Surtout lorsqu'on détient un pouvoir et lorsqu'un conflit peut rendre cette manœuvre suspecte. C'est la raison pour laquelle j'ai cru bon d'étudier, de traduire librement et de commenter la pratique anglophone sur laquelle tu avais pointé un lien : en:Wikipedia:User_page. Mon anglais et mon expérience wikipédienne sont insuffisants pour traiter honnêtement les 2 derniers points de cet article, ceux qui parlent précisément des points que tu soulevais. Pourrais-tu compléter donc Wikipédia:Pages personnelles ? Merci d'avance.
La mise au point concernant la paternité du paragraphe Pages personnelles que tu avais, semble-t-il, oublié de signer, ne visait donc pas à contester ton intervention mais à en contester la paternité. Wikinaute de quelques mois, je te trouvais en effet que la méprise d'Anthère — en m'attribuant la velléité de changer unilatéralement les règles régissant le bon usage des pouvoirs d'administrateur — me taillait le costume d'un présomptueux ridicule.
Amicalement, Roby 18 avr 2004 à 08:39 (CEST)
- Ok, message reçu.
Galicien
Hello. Une page a été créée sur Galicien par un non francophone. j'ai francisé le 1er §, mais je n'y connais rien et j'ai surtout pas compris la suite... ;o) Peut-être y arriverais-tu mieux que moi. si oui merci, sinon tant pis, j'y arriverai bien un jour. :o) a+ --Pontauxchats Ier|@ 18 avr 2004 à 10:19 (CEST)
- C'est gentil de penser à moi mais je n'ai vraiment plus le temps. Bon, je la garde affichée pour faire un tour quand l'occasion se présente. Vincent (discuter) 18 avr 2004 à 12:24 (CEST)
J'ai revu cet article et l'ai rendu compréhensible Fred091 18 avr 2004 à 12:52 (CEST)
- Merci.
J'ai ajouté la liste des liens (28 mai 2004).
Cher Vincent. Merci beaucoup pour ton mail; Cela fait deux jours que j'y pense :-) J'y réfléchi, j'y réfléchi et je pense qu'il va me donner une idée :-) Je te répondrai plus tard quand cela sera mûr :-) ant
- Il n'appelait pas forcément de réponse. Prends ton temps ;-) Vincent (discuter) 20 avr 2004 à 18:48 (CEST)
Qu'est-ce qu'un article Wiki ?
Déplacé depuis Bistro car lien rouge => non pertinent, ou à corriger & remettre sur le Bistro :) Ryo 23 avr 2004 à 10:58 (CEST)
Note : Le texte ci-dessous a été déplacé depuis le Bistro de Wikipédia pour alléger cette page qui ne cesse de s'allonger. Texte déplacé par : Vincent (discuter) 17 avr 2004 à 12:44 (CEST) dans Wikipédia:Le Bistro/Qu'est-ce qu'un article de Wikipédia ?
- Lien corrigé (la faute à l'insécable...).Vincent (discuter) 28 avr 2004 à 07:01 (CEST)
Chinese Translation
Your question answered : zh:Wikipedia:互助客栈 --Cylauj 25 avr 2004 à 20:48 (CEST)
- Thanks. Vincent (discuter) 25 avr 2004 à 21:00 (CEST)
lettrines des articles de linguistique
Dans de nombreux articles du domaines [linguistique] (y compris [écriture] et [langue]), une lettrine en image indique le sujet en VO, suivie, quelques mots plus loins, de la copie en unicode; par exemple « संस्कृतम् » pour [sanskrit]. ([Langues de l'Inde])
- dans sinogramme, Image:Hanzi image.png n'a pas de transcription en textuelle qui suive
- Le terme est donné en texte brut deux lignes plus bas. De toute façon, je viens de retirer l'image, devenue inutile.
- si quelqu'un souhaite remplacer ces lettrines en image par du texte, voici du code html + css : संस्कृतम्
- Je n'en vois pas trop l'intérêt, en fatit. Les écritures indiennes sont rarement correctement prises en charge par les navigateurs actuels. À supposer qu'un lecteur consultant cette page ait déjà les polices nécessaires installées dans son système, il y a fort à parier qu'il verra n'importe quoi, comme
 . C'est le cas pour moi actuellement (l'image est une copie d'écran de ce que je vois). Comme je sais lire la devanāgarī et me débrouille avec les autres semi-syllabaires de l'Inde, je corrige de moi-même (
. C'est le cas pour moi actuellement (l'image est une copie d'écran de ce que je vois). Comme je sais lire la devanāgarī et me débrouille avec les autres semi-syllabaires de l'Inde, je corrige de moi-même ( ). Je préfère qu'il reste une image pour éviter, dans l'état actuel des technologies, de produire une lettrine fausse. Vincent (discuter) 26 avr 2004 à 00:38 (CEST)
). Je préfère qu'il reste une image pour éviter, dans l'état actuel des technologies, de produire une lettrine fausse. Vincent (discuter) 26 avr 2004 à 00:38 (CEST)
- Excellente raison. (28 mai 2004)

MediaWiki langues IE
Salut Vincent, j'ai renoncé pour le moment à intégrer Modèle:LanguesIE à Wikipédia:Palettes de navigation/Linguistique : penses-tu que l'on pourrait subdiviser ce mediawiki en d'autres de tailles plus restreintes sous forme de tableaux ? ; Amaury 27 avr 2004 à 00:47 (CEST)
- Oui, j'y pense mais tous les problèmes n'ont pas été résolus, à savoir, principalement : où place-t-on les listes de langues ? Dans des articles à part ? Dans les articles de langues ? Il y a dans mes archives des discussions longues à ce sujet. Vincent (discuter) 27 avr 2004 à 06:43 (CEST)
- Je viens de procéder à un essai dans le bac à sable sous le titre Test langues IE, tes commentaires sont bienvenus, bien entendu. ; Amaury 28 avr 2004 à 01:37 (CEST)
- Cela ne semble pas mal. Mais le problème est tout autre, en fait. Vois dans Discussion Utilisateur:Vincent Ramos/Archives5 les débats possibles. Vincent (discuter) 28 avr 2004 à 15:53 (CEST)
- Il est vrai que beaucoup d'aspects sont à prendre en compte : que dirais-tu de lancer un espace de réflexion et d'action, sous la forme d'un projet, dédié à la question du langage ? ; Amaury 28 avr 2004 à 16:51 (CEST)
- En fait, actuellement je suis lancé dans un projet sur les sinogrammes qui me prend pas mal de temps. J'ai peur, si on lance une réflexion sur le sujet, de ne pas trop avoir la possibilité de m'y investir. Mais l'idée reste bonne. Vincent | 討論 28 avr 2004 à 17:43 (CEST)
- Il est vrai que beaucoup d'aspects sont à prendre en compte : que dirais-tu de lancer un espace de réflexion et d'action, sous la forme d'un projet, dédié à la question du langage ? ; Amaury 28 avr 2004 à 16:51 (CEST)
des modifications d'articles de langues
- Dans [MediaWiki:Sinogramme] :
- Le code CSS « border: inset purple; » ne prend pas de virgule entre inset et purple. La brodure violet apparait à présent.
- Il doit y avoir une plus grande tolérance à l'erreur de mon navigateur, qui m'affichait correctement la bordure. Et dire que j'ai participé à la relecture de la traduction officielle de documents concernant le CSS2 du W3C... Bravo la virgule.
- dans la norme CSS 2, des valeurs peuvent être énumérées et séparés par des virgules pour voice-family, font-family, et d'autres propriété.
- J'ai ajouté « width: 12em; » et supprimé les retours à la lignes dans les textes de descriptions des liens. Je ne sais pas si cela est correctement interprété par tous les logiciels
- Cela marche très bien pour moi.
- [lituanien]
- J'ai supprimé dans [vietnamien] le tableau (importé de en:) de ce que les participants de :en: doivent considérer comme les informations principales pour une langue. Je ne l'ai pas fait pour [lituanien], dans lequel la tableau a été ajouté par Utilisateur:Robin_Hood. Je ne suis pas sûr que ce soit ici le meilleur endroit pour en discuter.
- Vous avez bien fait. Je crois cependant qu'il va falloir lancer une concertation pour les langues afin qu'on trouve un modus operandi commun. Vincent | 討論 29 avr 2004 à 18:21 (CEST)
- Le tableau a été ajouté (apres plusieurs modifications) dans letton lituanien polonais sudovien vieux prussien
- Les tableaux sont insérés pour servir de référence rapide, et de nombreuses modifications ont été apportées, je crois, pour satisfaire aux divers types de navigateurs. Faudrait voir s'ils causent encore des problèmes, car même si j'ai inité le mouvement, j'y tiens pas mordicus. Robin des Bois 5 mai 2004 à 03:44 (CEST)
- En fait, nous en sommes encore à nous demander quelle est la meilleure solution. Il va falloire lancer une concertation sur le sujet car chaque article de langue a sa propre logique. Vincent | 討論 5 mai 2004 à 07:09 (CEST)
- D'accord avec toi, faudrait concensus. Mais qui va lancer la concertation? Pourrais-tu me tenir au courant? Robin des Bois 5 mai 2004 à 08:28 (CEST)
- Ben les personnes qui participent aux modifications des articlesde langue et de linguistique.
- D'accord avec toi, faudrait concensus. Mais qui va lancer la concertation? Pourrais-tu me tenir au courant? Robin des Bois 5 mai 2004 à 08:28 (CEST)
- En fait, nous en sommes encore à nous demander quelle est la meilleure solution. Il va falloire lancer une concertation sur le sujet car chaque article de langue a sa propre logique. Vincent | 討論 5 mai 2004 à 07:09 (CEST)
- Les tableaux sont insérés pour servir de référence rapide, et de nombreuses modifications ont été apportées, je crois, pour satisfaire aux divers types de navigateurs. Faudrait voir s'ils causent encore des problèmes, car même si j'ai inité le mouvement, j'y tiens pas mordicus. Robin des Bois 5 mai 2004 à 03:44 (CEST)
- Message à cette personne : pourquoi vouloir couper en deux, et le mettre deux fois, le lien [langues indo-européennes] ?
- Pas d'autre annulation de ma modification inverse dans le tableau
- Je vous ai posé beaucoup de question dans cette page (voir archives 4, 5 et 6), et vous m'avez répondu à la plupart. Je n'ai pas répondu, car la plupart de vos réponses m'ont fort satisfairte, confirmant ou contredisant ce que je pensais, mais m'étant profitables. Je tiens donc à vous remercier chaleureusement.
- [langue naturelle]] Je vous avais posé une question sur cet article :)
Vous l'avez relu plus tard, et avez corrigé. Cela amène plutôt à en sourire. Si vous préférez ne pas supprimer l'article, vouci ma modeste contribution :
« {msg:Ebauche}
Une [langue naturelle] désigne en [linguistique] le contraire d'une [langue construite].
[en:Natural language] [eo:Natura lingvo] [es:Lengua natural] [sw:Lugha Asilia] »
- Franchement, pour cette histoire de langue naturelle, je ne comprends pas comment j'ai laissé passer un tel truc ! Bien, votre bouchon et heureux d'avoir répondu à vos questions. Vincent | 討論 30 avr 2004 à 20:20 (CEST)
- Dans Langues par famille :
- Préambule
supprimer le troisième paragraphe ?
- Il ne me semble pas très important non plus. Vincent | 討論 5 mai 2004 à 07:09 (CEST)
- Je le fusionne avec le deuxième
- langues indo-européennes, langues germaniques, langues scandinaves :
supprimer la séparation entre sous-groupe occidental et sous-groupe oriental ? Le norvégien bokmål fait-il parti du sous-groupe occidental ?
- Les sous-groupes oriental / occidental sont bien reconnus. Le bokmål étant d'origine danoise, il fait bien partie du groupe occidental (voyez là). Vincent | 討論 5 mai 2004 à 07:09 (CEST)
- Vous voulez dire le sous groupe oriental ?
J'ai mis le bokmål dans le sous groupe oriental. C'est juste ? (28 mai 2004)
Langues balto-slaves
Bonjour Vincent. Comme tu sembles bien t'y connaître sur le sujet, j'ai besoin de tes lumières. J'ai constaté que dans la plupart des références sur Wikipédié, on place les langues baltes et les langues slaves dans le même groupe balto-slave. Pourtant, Je crois bien que depuis des années, les linguistes s'étaient entendus pour en faire deux groupes distincts malgré leur proche parenté. Après de nombreuses recherches sur les encyclopédies du web et en bibliothèque, j'ai trouvé bien peu de références appuyant cette union. Comme tu as dû le voir, j'ai fait plusieurs contributions dans ces langues et je voudrais éviter tout conflit d'édition s'il existe déjà un consensus. Robin des Bois 5 mai 2004 à 03:44 (CEST)~
- Pour moi, elles sont liées. Mais je suis tribuataire d'un enseignement linguistique qui peut parfois dater un peu. Je ne suis pas spécialiste de ce sujet mais les auteurs que je respectent par ailleurs pour leur bon sens les classent ensemble. D'autres, que je connais moins mais sont plus récents, les séparent. Je pense que les séparer est plus consensuel. Vincent | 討論 5 mai 2004 à 07:09 (CEST)
- Larousse et Glolier, pour ne nommer que les plus simples et répandus, les séparent. Je me propose pour modifier les articles que je rencontre pour faire cet ajustement, tout en mentionnant, si le contexte l'exige, que certaines écoles les considèrent comme un seul groupe. Est-ce un bonne idée? (En passant, j'ai laissé un petit mot à ton attention dans la page Discuter:Chaos (mythologie).) Robin des Bois 5 mai 2004 à 08:23 (CEST)
- (Si on convien de supprimer la page [balto-slave] et ses mentions dans d'autrse page) Techniquement, il suffit de demander les pages liées à [balto-slave], pour trouver les pages ayant un lien vers elle, et pourvoir enlever ces liens.
- Ouais, mais je vais attendre d'avoir les références exactes les plus récentes pour appuyer ce classement avant de tout changer. Robin des Bois 5 mai 2004 à 21:12 (CEST)
- Il faudrait demander dans news:sci.lang. Vincent | 討論 5 mai 2004 à 21:19 (CEST)
- Ouais, mais je vais attendre d'avoir les références exactes les plus récentes pour appuyer ce classement avant de tout changer. Robin des Bois 5 mai 2004 à 21:12 (CEST)
indiquer certaines tailles de polices
Pour Wikipédia:Test Unicode arabe et Wikipédia:Unicode/Test devanâgarî, pourriez vous indiquer quelle taille de police vous utilisates pour les images, afin de remplacer les « font size="+8" », qui sont sont imprécis et dépandent de la taille de base, par « font style="font-size: 30px;" »; pour que le texte et les images aient la même taille à l'affichage.
- Oups, je n'en sais trop rien... Vincent | 討論 3 mai 2004 à 14:48 (CEST)
- Tant pis. Ce n'est pas grave. on fera par approximations.
Note : le texte ci-dessous a été déplacé depuis le Bistro de Wikipédia. Ryo 4 mai 2004 à 09:58 (CEST)
Enthousiasme
Toute modestie gardée [sic], je suis très fier de moi : après avoir lutté avec Gimp, j'ai réussi à obtenir ce que je cherchais et que vous pouvez voir dans Radical (sinogramme).
Juste pour le dire, car je suis content. Vincent | 討論 29 avr 2004 à 19:22 (CEST)
- Superbe! Déjà que j'ai mis du temps à comprendre tracer une pauvre ellipse avec Gimp ... alors là! ;) Med 29 avr 2004 à 19:29 (CEST)
- Félicitations pour ton article VR. De belles images ! --youssef 29 avr 2004 à 19:37 (CEST)
- Absolument magnifique ! villy 29 avr 2004 à 19:42 (CEST)
- Un trés bel article, rajouté au panthéon des articles. Greudin (Discuter)
- En fait la mise au panthéon des articles nécessite un vote préalable :| Treanna 30 avr 2004 à 11:01 (CEST)
- Ah oui m*rde j'avais pas lu, je le déplace. Votez sur Proposition articles de qualité Greudin (Discuter)
ϐ vs. β
Salut, juste une petite remarque pour ϐ/β : il me semble que ϐ est une particularité franco-française, et que les autres pays mettent β partout, quelque soit la position dans le mot. Est-ce que ça te dit quelque chose ? D'ailleurs, il n'y a pas d'entité HTML pour ϐ (GREEK SYMBOL BETA), c'est pas une preuve ça ? ;-)
Pour les Synœcies, le Liddell-Scott accentue συνοίκια et non συνοικία. Jastrow 4 mai 2004 à 20:58 (CEST)
- Pour β/ϐ, j'ai écrit un paragraphe dans Variante contextuelle. C'est bien une particularité des éditions francophones. Je le défendrai donc bec et ongles car les bonnes éditions, Budé par exemple, l'utilisent toujours (bien que ce soit une sottise qu'aucune tradition ne peut justifier ; j'ai sous les yeux un fac simile d'une édition princeps française de poèmes en grec du XVIe siècle : le ϐ n'est bien sûr pas employé...).
- Pour les Synœcies, je n'ai regardé que le Bailly, qui ne connaît pas συνοίκια. Je n'ai pas le LS chez moi mais le consulte sur Perseus. Pour l'instant, il n'est pas accessible, mais tout à l'heure j'y ai fait un tour et il connaissait bien συνοικία. Je n'ai pas regardé συνοίκια, en revanche. J'essaierai de nouveau plus tard.
- Heureux de trouver un helléniste ici, Vincent | 討論 4 mai 2004 à 21:22 (CEST)
- Sinon, c'est un peu déroutant ce que tu dis pour le LS, que je consulte moi aussi via Perseus, donnerait-il les deux ? Le Lejeune va-t-il devoir départager les choses ?
- J'ai résolu l'affaire. En fait, si συνοίκια est possible, il faut que le dernier α soit bref : συνοίκιᾰ. Or, cette forme ne peut être que celle de l'adjectif au neutre pluriel (dont la désinence directe est un -ᾰ). Donc, c'est l'adjectif : συνοίκια (ἱερά), « (cérémonies) synœciennes ». Le nom, quant à lui, est bien συνοικία, avec -ᾱ final. Liddel le prouve :
- Or, vu la fréquence (deux attestations pour συνοίκιᾰ, soixante-douze pour συνοικίᾱ), je pense qu'il vaut mieux utiliser le nom, de même qu'on ne dit pas les « (cérémonies) panathénéennes » mais les Panathénées.
- Ah, et j'avoue : je suis quand même plus beaucoup plus latiniste qu'hélléniste. Comme Des Esseintes, je n'ai jamais pu accrocher le grec (ou le grec ne m'accroche pas, au choix), bien que je m'intéresse beaucoup à la civilisation et à l'art grecs... Jastrow 4 mai 2004 à 21:46 (CEST)
- Dommage... Je ne peux pas en dire autant car la langue grecque me plaît autant, si ce n'est plus, que sa civilisation. Content cependant d'avoir papoté de grec. Bonne continuation, en tout cas, Vincent | 討論 4 mai 2004 à 23:05 (CEST)
- Sinon, c'est un peu déroutant ce que tu dis pour le LS, que je consulte moi aussi via Perseus, donnerait-il les deux ? Le Lejeune va-t-il devoir départager les choses ?
- « Les bonnes éditions » : il y en a d'autres en France ? :)
- Oui, malheureuseument. Par exemple les Fables d'Ésope, édition bilingue traduite par Daniel Loayza chez GF-Flammarion : les β médians ne sont pas des ϐ.
- « Les bonnes éditions » : il y en a d'autres en France ? :)
- Merci de confirmer, je n'avais pas d'édition étrangère en grec chez moi pour ce faire.
- Tu n'as jamais travaillé sur des Loeb ? Ce que j'aime bien chez eux c'est que les textes papyrologiques utilisent c et non σ/ς (ce qui évite de devoir trancher : il n'est pas toujours aisé, dans un texte papyrologique, de savoir si un sigma est en fin de mot ou non).
- Je n'ai des Loeb qu'en latin (moins chers que les Budés, même en import)...
- Tu n'as jamais travaillé sur des Loeb ? Ce que j'aime bien chez eux c'est que les textes papyrologiques utilisent c et non σ/ς (ce qui évite de devoir trancher : il n'est pas toujours aisé, dans un texte papyrologique, de savoir si un sigma est en fin de mot ou non).
- Merci de confirmer, je n'avais pas d'édition étrangère en grec chez moi pour ce faire.
- Je vais essayer de mettre des ϐ médians, mais bon il faut bien avouer que ce serait plus facile avec un &varbeta;...
- Comment entres-tu le texte grec ? Sous Linux/Unix/BeOs, inclure le ϐ dans le clavier est très simple. Avec Windows, je sais aussi comment faire. Si tu es sous Mac non OS/X, désolé...
- Je suis sous FreeBSD, je n'ai pas encore tout passé en Unicode donc c'est tapé à la mimine, avec des entités HTML. Je copipaste depuis des tables Unicode les caractères accentués. Si tu as une méthode pour entrer le texte directement, ça m'intéresse.
- L'ami qui a amélioré ma disposition clavier pour entrer du grec polytonique est justement sous FreeBSD. Il devrait pouvoir t'aider. Quelle est ta locale ? Utf-8 ? Entre temps, je viens de lui envoyer un courriel. Vincent | 討論 5 mai 2004 à 06:48 (CEST)
- Justement, ma locale est bêtement fr_FR.ISO8859-1... Jastrow 5 mai 2004 à 13:11 (CEST)
- Tu dois pouvoir lancer une application en passant une autre locale, non ? Bon, j'attends la réponse de mon ami. Vincent | 討論 5 mai 2004 à 14:37 (CEST)
- Justement, ma locale est bêtement fr_FR.ISO8859-1... Jastrow 5 mai 2004 à 13:11 (CEST)
- L'ami qui a amélioré ma disposition clavier pour entrer du grec polytonique est justement sous FreeBSD. Il devrait pouvoir t'aider. Quelle est ta locale ? Utf-8 ? Entre temps, je viens de lui envoyer un courriel. Vincent | 討論 5 mai 2004 à 06:48 (CEST)
- Je suis sous FreeBSD, je n'ai pas encore tout passé en Unicode donc c'est tapé à la mimine, avec des entités HTML. Je copipaste depuis des tables Unicode les caractères accentués. Si tu as une méthode pour entrer le texte directement, ça m'intéresse.
- Comment entres-tu le texte grec ? Sous Linux/Unix/BeOs, inclure le ϐ dans le clavier est très simple. Avec Windows, je sais aussi comment faire. Si tu es sous Mac non OS/X, désolé...
- Je vais essayer de mettre des ϐ médians, mais bon il faut bien avouer que ce serait plus facile avec un &varbeta;...
Caractères spéciaux
À propos des caractères bizarres sous X11+Unix, j'utilise xmodmap (paraît-il obsolète avec X4.3 mais il marche quand même), très pratique. J'utilise AltGr pour obtenir π, œ, € ou «. Je n'ai pas encore trouvé le code pour l'espace insécable mais ça me travaille. ℓisllk★✉ 5 mai 2004 à 15:13 (CEST)
- Je n'utilise pas xmodmap, mais par défaut sous Mandrake, l'espace insécable s'obtient par « compose + espace + espace » Med 5 mai 2004 à 15:21 (CEST)
- Ayé, j'ai trouvé : « keycode 65 = space nobreakspace » fait que shift+espace donne l'espace insécable. Il suffit de lire /usr/X11R6/include/X11/keysymdef.h sur ma Sarge, d'y lire le nom du caractère et d'enlever le préfixe XK_ en gardant la casse. En en plus, les codes unicode hexadécimaux sont placés en regard. ℓisllk★✉ 5 mai 2004 à 15:41 (CEST)
- Quant à moi, j'utilise setxkbmap pour charger au démarrage une table de /usr/X11R6/lib/X11/xkb/symbols/pc/ que j'ai modifiée à la main, comprenant l'espace insécable et plein d'autres trucs, ainsi que la possibilité d'appeler une autre table, celle du grec polytonique. Je lance le tout avec -layout fr,el-poly -option "grp:shift_toggle", qui appelle les tables fr et el-poly, cette dernière m'ayant été tricotée à la main par un ami qui l'a publiée sous license BSD. Vincent | 討論
- Ça-y-est, tu es un vrai geek ! ℓisllk★✉ 5 mai 2004 à 16:01 (CEST)
- Eh oui... Remarque, c'est bien l'image que je donnais de moi avant à mon entourage : toujours devant mon clavier, c'est moi qu'on appelle pour dépanner les PC (voire un Mac, une fois !) des uns et des autres, je passe, dans mon milieu socio-professionnel, pour un spécialiste (alors que je pense plutôt que ma connaissance de l'informatique me permet de mesurer mes lacunes). Depuis mon passage à Linux, c'est devenu pire : la preuve, l'administrateur réseau de mon collège (une soixantaine de postes) m'a fourni tous les droits pour le seconder (sous NT...). Et tous de me faire confiance. Bon, reconnaissons-le, je suis une sorte de geek. Vincent | 討論 5 mai 2004 à 17:43 (CEST)
- Pareil sous Unix, je mesure l'étendue de mon ignorance en particulier sur les réseaux, et par extension un peu partout et surtout sur mon domaine de compétence : les maths. Je connais plutôt Linux (j'y bidouille), je suis un ignare sur Windows et pourtant on me qualifie de balaise en info. La bonne blague. Qu'on me donne à gérer le système du bahut et on va rire. ℓisllk★✉ 5 mai 2004 à 18:02 (CEST)
- Les mots Unix ou Linux sont lâchés : on crie au génie informatique. On ne me voit pas pester contre ces #%☁☗☠☹!!! de messages d'erreur incompréhensibles ! Vincent | 討論 5 mai 2004 à 18:26 (CEST)
- Pareil sous Unix, je mesure l'étendue de mon ignorance en particulier sur les réseaux, et par extension un peu partout et surtout sur mon domaine de compétence : les maths. Je connais plutôt Linux (j'y bidouille), je suis un ignare sur Windows et pourtant on me qualifie de balaise en info. La bonne blague. Qu'on me donne à gérer le système du bahut et on va rire. ℓisllk★✉ 5 mai 2004 à 18:02 (CEST)
- Eh oui... Remarque, c'est bien l'image que je donnais de moi avant à mon entourage : toujours devant mon clavier, c'est moi qu'on appelle pour dépanner les PC (voire un Mac, une fois !) des uns et des autres, je passe, dans mon milieu socio-professionnel, pour un spécialiste (alors que je pense plutôt que ma connaissance de l'informatique me permet de mesurer mes lacunes). Depuis mon passage à Linux, c'est devenu pire : la preuve, l'administrateur réseau de mon collège (une soixantaine de postes) m'a fourni tous les droits pour le seconder (sous NT...). Et tous de me faire confiance. Bon, reconnaissons-le, je suis une sorte de geek. Vincent | 討論 5 mai 2004 à 17:43 (CEST)
- Ça-y-est, tu es un vrai geek ! ℓisllk★✉ 5 mai 2004 à 16:01 (CEST)
- Quant à moi, j'utilise setxkbmap pour charger au démarrage une table de /usr/X11R6/lib/X11/xkb/symbols/pc/ que j'ai modifiée à la main, comprenant l'espace insécable et plein d'autres trucs, ainsi que la possibilité d'appeler une autre table, celle du grec polytonique. Je lance le tout avec -layout fr,el-poly -option "grp:shift_toggle", qui appelle les tables fr et el-poly, cette dernière m'ayant été tricotée à la main par un ami qui l'a publiée sous license BSD. Vincent | 討論
- Ayé, j'ai trouvé : « keycode 65 = space nobreakspace » fait que shift+espace donne l'espace insécable. Il suffit de lire /usr/X11R6/include/X11/keysymdef.h sur ma Sarge, d'y lire le nom du caractère et d'enlever le préfixe XK_ en gardant la casse. En en plus, les codes unicode hexadécimaux sont placés en regard. ℓisllk★✉ 5 mai 2004 à 15:41 (CEST)
Alpha
Dans le même genre, le alpha est α, et je l'ai toujours tracé en forme de petit poisson, avec la patte supérieure qui dépassait. C'est grave, docteur ? ℓisllk★✉ 5 mai 2004 à 13:00 (CEST)
- J'imagine que tu n'es pas helléniste : je dis cela parce que j'ai souvent remarqué que les scientifiques traçaient les lettres grecques à la 6 4 2 (j'exagère un peu), surtout alpha α, théta θ et gamma γ. Pour théta, Unicode prévoit un caractère bis, ϑ U+03D1 (de même pour kappa, pi, etc.). Je dirais que ce n'est pas grave, mais bon, qu'on ne t'y reprenne plus. Vincent | 討論 5 mai 2004 à 14:37 (CEST)
- Aïe, pas la tête ! Je connais l'alphabet grec (astronomie aidant) mais effectivement je ne cause pas le grec, je le déchiffre mais je n'y comprends pas grand-chose : je comprends quelques mots grace à l'étymologie mais je ne saurais ni lire le grec moderne à haute voix ni le grec ancien. Il va bien falloir que je m'y mette un jour, comme au latin et à l'arabe. ℓisllk★✉ 5 mai 2004 à 14:54 (CEST)
- Oui, et plus vite que cela ! Vincent | 討論 5 mai 2004 à 15:38 (CEST)
- Aïe, pas la tête ! Je connais l'alphabet grec (astronomie aidant) mais effectivement je ne cause pas le grec, je le déchiffre mais je n'y comprends pas grand-chose : je comprends quelques mots grace à l'étymologie mais je ne saurais ni lire le grec moderne à haute voix ni le grec ancien. Il va bien falloir que je m'y mette un jour, comme au latin et à l'arabe. ℓisllk★✉ 5 mai 2004 à 14:54 (CEST)
Parthénon
Je suis passée voir l'article, c'est du beau boulot ! J'ai fait un peu de wikification et j'ai ajouté quelques détails (financement de la construction, comparaison avec les autres temples). Jastrow 6 mai 2004 à 12:49 (CEST)
- Merci. Je me suis servi de mes propres cours... Je viens de regarder la version anglophone : elle n'est pas mal et je pense qu'il y a encore matière à récupérer (dont les images ─ si leur copyright est clair). Je compte faire un plan du temple pour illustrer les notions architecturales. Vincent | 討論 6 mai 2004 à 18:22 (CEST)
Retranscription du grec
Salut Vincent,
Pour l'article Athènes, j'ai traduit/transcrit différents noms (maire, municipalités de la mégalopole). J'ai demandé vérification à une amie grecque, elle m'a répondu ceci, où elle m'explique le problème du nom au génitif au lieu du nominatif. Il faut donc choisir une convention : soit les noms sont mis au nominatif avant transcription, soit au génitif. L'avantage du nominatif, c'est que ça sonne plus familier (-polis au lieu de -poli) ; l'avantage du génitif, c'est que ça colle à l'usage grec ('fin d'après ce que j'ai compris, elle a pas été claire en ce qui concerne les municipalités qui ont l'air d'être au nominatif en grec et qu'elle a mis au génitif pour la transcription, mais là elle s'est absentée pour la semaine donc je peux pas lui demander). Qu'en penses-tu : nominatif ou génitif ? Merci de tes lumières ;-) Alibaba 9 mai 2004 à 16:57 (CEST)
- J'en pense que c'est assez difficile de répondre. À mon avis, il faut
- coller à l'usage français quand il existe (ce qui me semble en fait fort rare) ;
- proposer les deux graphies (quitte à mettre le s entre parenthèses, par exemple).
- Le nominatif est la forme du dictionnaire. Mais certaines Grecques sont connues en France sous leur nom au génitif, comme Nena Venetsanou (Νένα Βενετσάνου)... Je ne sais pas trop quoi te dire. Vincent ✐ 9 mai 2004 à 18:47 (CEST)
SOS Bailly
Salut Vincent, j'ai un trou terrible concernant la traduction de « ἑκάεργος » (c'est pour la page sur Apollon, rubrique « épithètes »). À l'étymologie, je dirais que ça veut dire « qui a le bras long », mais ça fait moyennement épique. Saurais-tu quelle est la traduction officielle ? Jastrow 12 mai 2004 à 20:13 (CEST)
- La traduction du Bailly est : « qui repousse au loin (avec ses flèches) ». J'ajoute que l'étymologie n'est pas claire mais qu'on peut y trouver ἕκας (ἑκάς en ionien-attique), « au loin ». Cf. ἑκηϐόλος, « qui lance au / de loin ». Vincent ✐ 12 mai 2004 à 20:28 (CEST)
- Merci. Ça explique pourquoi Leconte de Lisle traduit simplement par « l'Archer ». En revanche, Mazon traduit par « le Préservateur », pas glop... Jastrow 12 mai 2004 à 20:45 (CEST)
langues satem et langues centum
L'image sv:Bild:Indoeuropeiska_sprak_trad.jpg classe (divise) les [langues indo-européennes] en [langue satem] et [langue centum]. Il y a aussi des listes dans en:satem et en:centum
Est-ce exact ? Est-ce un classement à faire (aucune page sur les langues indo-européennes dans les autres langues ne le fait pour la liste des langues, sauf af:Indo-Europees, nl:Indo-Europese talen en commentaire de langue, sv:Indoeuropeiska språk dans l'image d'illustration), sachant qu'il est écrit « Non que cette opposition soit importante en soi » dans [langues indo-européennes].
N'hésitez pas à me répondre que vous ferez les articles [langue satem] et [langue centum] dans six ou douze mois, si c'est votre intention.
- C'est le cas ;-) En fait, la distinction entre les deux groupes est surtout importante au linguiste comparatiste et pour la compréhension de certains mécanismes phonétiques que ─ sans cela ─ on ne pourrait expliquer. Sorti de ce domaine, l'isoglosse qu'on peut tracer montre une répartition (presque) nette entre langues de l'Ouest et langues de l'Est, ce qui pourrait faire penser à un mouvement migratoire des Indo-Européens. Pourtant, cela ne coïncide pas avec les dates : les langues les plus anciennes ne sont en effet pas forcément du même côté de l'isoglosse : le sanskrit est satem, le grec centum. Vincent ✐ 14 mai 2004 à 19:12 (CEST)
Salut Vincent, sais-tu ù on pourrait mettre un lien à cet article? N'y a-t'il pas déjà qqch du même genre? -- Looxix
- Il y a déjà Diacritiques et Diacritiques de l'alphabet latin. Je prévoyais de faire, un jour, un tel article (en plus développé), et il en existe déjà un bout Accent circonflexe en français. Je m'en occupe (il suffit de déplacer et de supprimer les redites en liant correctement). Vincent ✐ 16 mai 2004 à 21:28 (CEST)
- C'est fait. Vincent ✐ 16 mai 2004 à 21:59 (CEST)
Noms grecs
Voici une petite liste de noms à vérifier
- Sisyphe Σισυφύς Sisyphus
- Protée Πρωτεύς Proteus
- Olympe Ὄλυμπος Olympos
- Odyssée Ὀδυσσεία Odysseía
- Tantale Ταντάλος Tantálos
- Pélops Πελοπς Pélops
- Déméter Δημήτηρ Dêmêter
- Styx Στυξ Styx
Dans ton dernier message, tu utilises Ἀνδρομέδα avec l'esprit sur l'alpha initial. Si j'ai bien compris, c'est parce qu'il s'agit d'un nom grec ancien et l'usage moderne écrirait Aνδρομέδα ? L'usage de Gorgonéion se limite-t-il seulement au bouclier, et sert-t-il à désigner aussi toute représentation de la tête de la Gorgone ? Tu peux répondre sur la section du même nom de ma page de discussion. Robin des Bois ♘ ➳ ✉ 18 mai 2004 à 20:54 (CEST)
- Je réponds ici, c'est plus simple. Pour l'esprit : tu l'as bien compris, seuls les mots en grec ancien utilisent l'esprit (voir Diacritiques de l'alphabet grec ─ je vends mes articles ;-). Mais il y a un autre problème : pour des raisons stupides, Unicode a codé différemment l'accent aigu ancien et l'accent simple actuel (alors que ce devrait être le même caractère). J'ai choisi de n'utiliser que l'accent aigu moderne car c'est celui que les polices de caractères ont le plus souvent (en fait, dès qu'elles ont ce qui faut pour afficher le grec polytonique ─ à plusieurs accents, esprits et iota souscrit : ήὴῆἠἡῃ, etc. ─ elles ont aussi l'accent monotonique).
- Ainsi, dans Ἀνδρομέδα j'utilise l'accent aigu moderne. Ἀνδρομέδα écrit ainsi est une sorte de monstre car je mélange des caractères polytoniques (Ἀ) et monotoniques (έ). Pour bien faire, il faudrait écrire Ἀνδρομέδα (tu devrais lire la même chose mais les deux ε accent aigu ne sont pas les mêmes caractères). Écrire Ἀνδρομέδα permet que plus de lecteurs puissent le lire et, surtout, est plus simple pour moi à gérer. Bon, je répondrai au reste plus tard. Vincent ✐ 18 mai 2004 à 23:35 (CEST)
Merci pour le petit mot Vincent. J'avais déjà fait les modifications et ajouts dans les pages concernées. J'ai copié/collé les termes pour êtres sûr de ne pas faire d'erreurs de caractères. Je me suis servi de ta méthode pour les insérer : (en grec motgrec aplhabetlatin) Robin des Bois ♘ ➳ ✉ 23 mai 2004 à 03:30 (CEST)
- Ok. Comme une modification en chasse une autre, je n'étais pas sûr que tu aies vu mon ajout dans ta page. J'ai aussi, dans la page de discussion de ta page d'utilisateur en chinois, apporté quelques informations Vincent ✐ 23 mai 2004 à 03:33 (CEST)
- Hmmm! As-tu été voir TOUTES mes pages perso dans les autres langues ? Si c'est le cas, merci de ton encadrement. Je suis humblement honoré ;-) Robin des Bois ♘ ➳ ✉ 23 mai 2004 à 06:31 (CEST)
- Oui. Non pas que je te pistes : je suis déjà casé ;-) Simplement, une fois où je suis passé par ta page d'utilisateur pour accéder à ta page de discussion, j'ai vu la foultitude de liens interwiki vers les autres pages. Or, il est rare qu'un contributeur qui n'est pas là depuis longtemps ait plusieurs pages d'utilsateur. En tout cas, pas tant. La curiosité aidant, je suis allé faire un tour... Vincent ✐ 23 mai 2004 à 09:17 (CEST)
- Ah, bon! Il semble donc que la curiosité est une autre qualité que nous ayons en commun. Je me suis créé tous ces comptes pour de simples raisons pratiques. De plus, si ça fait en sorte que plus de gens prennent contact entre wikis de langues différentes, je fais d'une pierre, deux coups. Dernier petit nom grec pour toi: Charon Χαρον. À bientôt! Robin des Bois ♘ ➳ ✉ 14 jun 2004 à 22:11 (CEST)
- Oui. Non pas que je te pistes : je suis déjà casé ;-) Simplement, une fois où je suis passé par ta page d'utilisateur pour accéder à ta page de discussion, j'ai vu la foultitude de liens interwiki vers les autres pages. Or, il est rare qu'un contributeur qui n'est pas là depuis longtemps ait plusieurs pages d'utilsateur. En tout cas, pas tant. La curiosité aidant, je suis allé faire un tour... Vincent ✐ 23 mai 2004 à 09:17 (CEST)
- Hmmm! As-tu été voir TOUTES mes pages perso dans les autres langues ? Si c'est le cas, merci de ton encadrement. Je suis humblement honoré ;-) Robin des Bois ♘ ➳ ✉ 23 mai 2004 à 06:31 (CEST)
Merci. Au fait, à propos de ta question sur la sybille de Cumes dans [Discuter:Charon (Mythologie)], j'avais bien raison. Il s'agit de l'Énéide VI, qui raconte le voyage d'Énée aux Enfers, accompagné de la prêtresse. Euh, en passant, pourrais-tu m'expliquer pourquoi certaines pages wikipédia, notamment en chinois, en coréen et récemment en français, m'apparaissent maintenant en caractères énormes, malgré le réglage de ma taille d'affichage ? Serais-ce un nouveau réglage du /monobook.css que je devrais effectuer? Robin des Bois ♘ ➳ ✉ 15 jun 2004 à 03:00 (CEST)
- Là, je ne vois pas. Il faudrait que tu m'indiques des pages où cela se produit. Vincent ✑ 15 jun 2004 à 07:08 (CEST)
- Sur toutes les pages en français, en japonais, en coréen et en chinois. Le problème a commencé quand j'ai fait une actualisation de ta page, comme si un bug s'installait dans la configuration par défaut de la page. Et les onglets en haut changent de position et s'alignent à la verticale quand on les survolent de la souris. IE ne me donne aucun message d'erreur. Que me conseilles-tu de faire (ou d'essayer) ? Robin des Bois ♘ ➳ ✉ 15 jun 2004 à 07:28 (CEST)
Salut,
Si tu pouvais voir si je ne dis pas trop de bétises...
Ce n'est qu'un début.
Merci d'avance Nataraja-Shiva 20 mai 2004 à 11:18 (CEST)
- J'ai surtout développé l'articles sur les emprunts aux langues amérindiennes. J'ai quelques questions sur les mots bardai et kamise : peux-tu m'indiquer quelles sont tes sources pour dire que le premier est bien relié à barde (ce que ne mentionne pas le Dictionnaire étymologique de la langue latine d'Ernout et Meillet) et que le second ne serait pas un emprunt d'une langue indienne au portugais, ce qui me semblerait plus logique. En effet, le même dictionnaire étymologique signale des formes proches dans les langues germaniques mais pas pour des langues indiennes.
- J'ai donc du mal à croire qu'il y a là des termes hérités de l'indo-européen mais j'y vois plus 1) une coïncidence comme il en eixste tant, 2) un emprunt croisé.
- D'autre part, cash en anglais ne vient pas d'une langue indienne mais de l'anglo-normand, forme d'ancien français, caisse, ce qui m'est confirmé par plusieurs dictionnaires de langue anglais ainsi que L'Étymologie anglaise de Paul Baquet (« Que sais-je ? » n° 1652). Pour les dicos en ligne, voir http://www.etymonline.com/c2etym.htm, http://www.bartleby.com/61/2/C0140200.html (American Heritage). En revanche, il existe un autre mot cash (cash2) venant du tamoul par portugais et désignant cette fois-ci une monnaie asiatique trouée au centre (et non le cash au sens français). Or, le mot cash français ne vient pas de ce cash2 mais de cash1. Le TLFi confirme, mais le Robert historique ni le Bloch et Wartburg ne citent ce mot.
- Pour les autres mots, je suis d'accord.
- Vincent ✐ 20 mai 2004 à 12:59 (CEST)
- Ok Pour chemise je l'avais gardé dans le doute, mais reclassé, du rédacteur précédent. Souvent entendu en Inde. Pour cash et bardai, je me basais sur le Dictionnaire de la civilisation indienne de Louis Frédéric. Peut-être une source peu sûre.
- Je ne dis pas que kamise ne s'utilise pas, mais je pense plus simple de considérer qu'il s'agit d'un emprunt à une langue européenne comme le portugais. Ah, le dictionnaire d'ourdou et d'hindi classique de Platts semble confirmer : « qamīṣ, vulg. qamīz, kamīj, s.m. A shirt; a shift; a chemise (cf. It. camicia; Port. camisa) ». C'est bien un emprunt.
- Pour bardai, j'ai beau chercher (et j'en ai, des dicos), je ne le trouve nulle part. Cela signifie sans doute qu'il est mal transcrit (vois pour kamise, qu'il faudrait écrire qamīṣ).
- Si tu veux un terme IE vraiment hérité et non emprunté, tu as l'embarras du choix. Par exemple hindi baṛbaṛ, (sanskrit barbara-) « gromellement » = grec βάρϐαρος bárbaros « personne qui bredouille » = « barbare » (cf. Redoublement).
- Louis Frédéric est quelqu'un dont j'apprécie beaucoup le travail. Mais comme souvent dans ce genre d'ouvrages, il n'a pas pu tout vérifier.
- Pour les mots que nous ont fournis les langues indiennes, tu peux consulter L'Aventure des mots français venus d'ailleurs d'Henriette Walter. Si tu ne l'as pas, je t'en donne quelques exemples. Sinon, une recherche étymologique avec le Petit Robert électronique (pareil : si tu n'as pas, je chercherai). Tu peux penser à punch (IE), coprah (non IE : tamoul), patchouli (tamoul), vétiver...
- Est-ce qu'il existe un équivalent de http://www.etymonline.com/ pour le français ?
- Nataraja-Shiva 20 mai 2004 à 18:12 (CEST)
- Pas à ma connaissance. Le TLFi possède cependant de bonnes rubriques étymologiques. Vincent ✐ 20 mai 2004 à 19:55 (CEST)
- Ok Pour chemise je l'avais gardé dans le doute, mais reclassé, du rédacteur précédent. Souvent entendu en Inde. Pour cash et bardai, je me basais sur le Dictionnaire de la civilisation indienne de Louis Frédéric. Peut-être une source peu sûre.
Justice
J'envisage, à contrecoeur, de reprendre en profondeur la page Justice qui me donne de l'herpès en l'état actuel. Dans l'hypothèse où les oeufs de Pâques n'auraient pas dégradé nos relations de manière irréversible, ce qui serait quand même dommage au regard du caractère sucré et moelleux du sujet, pourrais-tu me fournir quelques mots ou lignes sur l'étymologie du mot, ici ou directement en tête d'article ? Merci de ce que tu pourras faire. villy 21 mai 2004 à 08:28 (CEST)
- Beuh, pourquoi nos relations auraient-elles été entachées ? Nous avons discuté de manière courtoise et sensée. Pour justice (bon courage, c'est le type même d'articles qui me donne la nausée, mutatis mutandis), je peux te fournir une étymo, que je placerai directement dans l'article. Vincent ✐ 21 mai 2004 à 19:06 (CEST)
- Merci beaucoup, vraiment, ça me fournira l'impulsion de départ dont j'ai besoin. villy 21 mai 2004 à 23:47 (CEST)
J'ai rétabli les choses telles qu'elles étaient lorsque la situation ne semblait pas en mesure d'occasionner tant de dégâts physiologiques, j'espère que la petite modification sur la page utilisateur de villy a été prise pour pour ce qu'elle est (une boutade) : je pensais au caractère imbuvable de l'article justice depuis un moment et avais même pensé en parler à notre brillant magistrat mais m'étais abstenu étant données les réserves qu'il a pu émettre quant à sa participation aux articles traitant de son environnement professionnel ; puisqu'existe Modèle:Série Justice, Modèle:Droit pourrait être proposé à la suppression voire que la demande en soit faite de façon directe à un administrateur puisque je (son auteur) ne m'oppose à ladite suppression : à villy de voir quel(s) nom(s) et quel(s) contenu(s) de MediaWiki(s) sur le thème est/sont le plus pertinent(s) ; je profite de ce message pour transmettre à Vincent combien j'ai apprécié sa prose aux liens étranges sur Haaahaaahaaa de Pontauxchats et ses prouesses sur Gimp (remarquées avant le mot sur le bistrot mais devant le concert d'éloges une couche de plus m'était alors apparue comme inutile, cependant les compliments sont en général bons à prendre tant que restent surveillées les circonférences du crâne et des chevilles, alors voilà ;-) et à villy que je lui souhaite aussi bon courage pour l'article auquel il s'attaque en espérant lui avoir rendu la pente moins raide. ; Amaury 22 mai 2004 à 04:24 (CEST)
Merci Vincent pour ton message (je l'ai transmis à villy). ; Amaury 26 mai 2004 à 17:24 (CEST)
Comprends-tu l'islandais?
Salut Vincent, si tu comprends ou décryptes quelque peu l'islandais pourrais-tu me dire plus ou moins ce qui se trouve sur cette page is:Wikipedia:Stjórnendur (je crois que c'est une demande pour être sysop; mais je n'en suis pas sûr). Merci d'avance. -- Looxix
- Très balaise car les racines germaniques ne sont pas mon fort et cette langue n'utilise pour ainsi dire aucun mot savant tiré du latin ou du grec. En gros, cela parle d'« administrateurs sur Wikipédia » (Stjórnendur á Wikipedia), « qui sont ceux qui ont » (eru þeir sem hafa) « les droits aussi dits de sysops » (svokölluð 'sysop' réttindi). Le reste est beaucoup plus flou. Il est question, en vrac, de « ce que le programme de Wikipédia (ou la direction de Wikipédia) » « attribuer (je continue mot à mot) tel droit quelqu'un... volontairement jusqu'à... tout ceux qui ont falloir devenir administrateur de Wikipédia »... J'arrête là, c'est trop dur car la phrase est trop longue (et en plus, j'ai laissé tomber tous les cas et j'ignore la syntaxe).
- La suite dit (traduction intuitive et sûrement très fautive) « les administrateur n'ont aucun autre pouvoir particulier excessif (?) sur Wikipédia en ce qui concerne la rédaction d'articles (?) et ont accès aux quelques zones qui sont réservées / fermées ... général par sécurité ».
- Enfin :
- « les admins peuvent :
- (peut-être) bloquer/débloquer des pages (?) ;
- modifier des pages bloquées ;
- effacer des pages ;
- Etc., le reste se comprend facilement (bloquer des IP, etc.). J'espère malgré tout t'avoir été quelque peu utile. Pour le coup, je ne brille pas trop... Vincent ✐ 22 mai 2004 à 00:17 (CEST)
- Magnifique! Il s'agit donc bien de l'équivalent de la page Wikipédia:Administrateur. Merci beaucoup. A+ -- Looxix
Danemark ou Danemark ?
Salut Vincent, j'ai encore un service à te demander: est-ce qu'on dit "royaume du Danemark" ou "royaume de Danemark"? Pareil pour "Harald II du Danemark" ou "Harald II de Danemark"? Y-a-t'il une règles à ce sujet ou c'est l'usage qui décide? Merci d'avance. -- Looxix 24 mai 2004 à 23:26 (CEST)
- Honnêtement, je ne sais pas. De plus, Google donne des chiffres proches pour les deux emplois. Quant à savoir si une règle existe ou bien si c'est l'usage... Mes différentes sources n'en parlent pas. Si la question est importante, j'irai la poser surdansà news:fr.lettres.langue.francaise : j'y suis bien reçu. Vincent ✐ 24 mai 2004 à 23:48 (CEST)
- [1] Une réponse sur le pourquoi du probléme, j'ai cherché dans une base de données et les auteurs du 19iéme utilise "de Danemark" ou "en Danemark" phe 25 mai 2004 à 00:02 (CEST)
langues ouraliennes
Et personne ne pouvait me dire que je m'était trompé dans les articles des langues ouraliennes ?! (28 mai 2004)
- Désolé, je ne m'en étais pas aperçu. Vincent ✐ 28 mai 2004 à 17:31 (CEST)
J'ai finis par m'en rendre compte, en faisant une vérification générale des articles des langue aujourd'hui. (28 mai 2004)
Note pour plus tard : penser à synchroniser [langues indo-européennes] avec [langues par famille] (je pense avoir synchronisé dans le sens inverse) (28 mai 2004)
langues slaves
Allez vous mettre en application les principes énnoncés dans [Discuter:Langue_romane] sur les articles des [langues slaves], en particulier Utilisateur:213.191.148.136 et Utilisateur:213.191.130.179 ?
- Voyez les modifications de cette personne, telles : le serbo-croate comme invention communiste (et les conséquences dans tous les articles des langues, surtouts ceux des langues slaves), le bosnien (sic), le bélarus (sic)...
- Ah... Je ne connais pas assez le sujet pour argumenter. Du moins, ce que je connais pourrait être dépassé. Je préfère me taire. Vincent ✐ 30 mai 2004 à 23:45 (CEST)
- J'ai une question plus générale pour Vincent: comment fait-on pour savoir si l'on est en présence d'une langue ou d'un dialecte? Jyp 30 mai 2004 à 23:52 (CEST)
- On ne fait pas : il n'y a pas de différence objective. Qualifier telle langue de dialecte / patois ou de langue ressortit à la politique, la culture ou l'histoire mais pas à la linguistique. En effet, aucun critère formel n'existe. Pour moi, les seules différences objectives sont :
- langue ;
- pidgin ;
- créole (ancien pidgin devenu langue).
- Sorti de cela, il n'y a rien de précis. Si la question t'intéresse, je peux chercher dans The Power of Babel de MacWhorter, qui consacre, pour démonter ce mythe, une grande partie de son ouvrage. Les exemples abondent. Vincent ✐ 31 mai 2004 à 00:19 (CEST)
- Cela confirme ce que j'avais compris: c'est un acte politique de ces pays qui utilisent la langue comme moyen de promouvoir leur identité nationale. Jyp 31 mai 2004 à 19:31 (CEST)
- Exact. Voir par exemple ce qu'on appelle en France des patois, le serbe et le croate qui sont considérées comme des langues alors qu'elles sont plus que très proches et intercompréhensibles, et les dialectes chinois, nommés ainsi alors qu'il n'y a d'intercompréhension qu'à l'écrit. Tout cela n'est que culturel et surtout politique. Vincent ✐ 31 mai 2004 à 23:04 (CEST)
- Cela confirme ce que j'avais compris: c'est un acte politique de ces pays qui utilisent la langue comme moyen de promouvoir leur identité nationale. Jyp 31 mai 2004 à 19:31 (CEST)
- On ne fait pas : il n'y a pas de différence objective. Qualifier telle langue de dialecte / patois ou de langue ressortit à la politique, la culture ou l'histoire mais pas à la linguistique. En effet, aucun critère formel n'existe. Pour moi, les seules différences objectives sont :
Recherches avec Google
Bonjour,
Il se passe une chose étrange avec Google, au moment où j'écris, du moins. Toutes les recherches que j'y lance concernant un article de Wikipédia (sans spécifier le site sur lequel limiter la recherche) semblent exclure Wikipédia. Il est simple de le constater avec des articles que j'ai écrits qui ne se trouvent nulle part ailleurs sur la web (Apophonie accentuelle en russe, Phonème éphelcystique) ou d'autres qui, il y a peu, étaient toujours classés en premier : ils sont maintenant absents d'une recherche et seuls les miroirs apparaissent. Étrange, non ?
Par exemple... Vincent ✐ 4 jun 2004 à 12:41 (CEST)
Salut, j'ai essayé avec le lien que tu as donné et chez moi le premier lien est un lien vers la wikipedia (fr.wikipedia.org). Peut-être qu'un robot était en train de parcourir le site quand tu as essayé et que quand ils parcourent, ils éffacent d'abord tous les liens (je ne sais pas comment fonctionne google en interne)
- Cela marche ici aussi. Mais il y a plusieurs serveurs google, répartis dans différents pays, et il ne sont pas toujours synchronisés. Il faudra surveiller si c'était un phénomène isolé et temporaire où si le problème se répend. Jyp 4 jun 2004 à 14:00 (CEST)
- Maintenant, tout est bon. En fait, j'ai l'impression que Google a été hacké pendant quelques dizaines de minutes. En effet, quelle que fût la recherche, un lien vers un site de téléchargement de MP3 était cité en premier puis, sous ce site, quelques autres sans trop de rapport, mais toujours les mêmes. Étrange.
- Ca ressemble plus à un DNS poisonning. Jyp 5 jun 2004 à 11:29 (CEST)
- Maintenant, tout est bon. En fait, j'ai l'impression que Google a été hacké pendant quelques dizaines de minutes. En effet, quelle que fût la recherche, un lien vers un site de téléchargement de MP3 était cité en premier puis, sous ce site, quelques autres sans trop de rapport, mais toujours les mêmes. Étrange.
Heuh, Екатери́на je suppose que ça veut dire Catherine ;o) mais vu mes connaissances en Russe, j'ai pas osé rectifier... heMmeR 4 jun 2004 à 13:46 (CEST)
Numération vicésimale et soixante-dix
Salut Vincent. On se posait une question avec quelques wikipédiens. Quelle est l'orgine de « soixante-dix » (on ne dit pas « quarante-dix » pour « cinquante »...)? Autant « quatre-vingt » et « quatre-vingt-dix » seraient expliqués par un ancien système de numération vicésimale utilisé par les Gaulois, autant pour « soixante-dix » on ne voit pas d'explication. On se dit que cela devrait être « trois-vingt-dix ». Mais force est de constater que ce n'est pas le cas. Aurais-tu quelques lumières à nous apporter concernant cette délicate question? Merci d'avance Med 5 jun 2004 à 15:32 (CEST)
- Oui. Cette question n'est pas résolue mais cela fait un petit moment que l'on exclut une origine gauloise (voir à Gaulois) ou, du moins, que celle-ci est fortement critiquée. C'est une question dont nous avons très souvent débattu dans news:fr.lettres.langue.francaise. Vous pouvez consulter les archives par Google. Par exemple : cet article ou celui-là. Vincent ✐ 5 jun 2004 à 15:42 (CEST)
- Merci Vincent. Je pense qu'on pouvait encore se poser la question longtemps. Si même les spécialistes n'ont pas de réponse définitive, alors ... Med 5 jun 2004 à 16:01 (CEST)
- Une petite remarque: les textes en français "ancien" (ex. Molière) utilisent septante, huitante et nonante, qui sont (partiellement) restés en usage en Suisse et en Belgique (Il y a aussi un bâtiment parisien qui s'appelle «l'hôtel (ou l'hôpital) des six-vingts»). Cela tend néanmoins à corroborer une invention récente (postérieure à Molière), ou alors leur origine allogène à la langue parlée à l'époque. Jyp 5 jun 2004 à 15:51 (CEST)
- Il y a même aussi l'« hôpital des quinze-vingt », en référence aux trois cent malades qu'il pouvait accueillir lors de sa fondation. Med 5 jun 2004 à 16:01 (CEST)
Voyelles latines en API
Salut Vincent. Alors que je m'attèle à l'amélioration de Ancien français, j'hésite sur la transcription des voyelles latines en API. Moi j'ai étudié la linguistique historique avec l'alphabet des romanistes : 5 voyelles latines x 2 longueurs = ā ă ē ĕ... Mais comme je voudrais écrire l'article en API, je me demande si on utilise un autre système pour la phonétique latine dans ce cas. Tu peux peut-être m'éclairer ? --Serge(iNyar)
- En fait, je trouverais plus simple de garder pour le latin le système de Bourciez / alphabet romaniste car c'est celui que tout étudiant en lettres a étudié (au contraire de l'API). Mais bon.
- Tout d'abord, je pense qu'il n'est pas possible de fournir une notation phonétique mais seulement phonologique, donc entre barres obliques. En effet, nous ne savons rien de la réalisation physique et articulatoire exacte des sons latins (les auteurs antiques ayant traité de phonétique ne sont en effet jamais aussi rigoureux que ce que demande une transcription phonétique) et la seule chose qui importe est leur traitement en tant que phonèmes. Donc : transcription phonologique, j'insiste. On laissera de côté certains détails, ou bien ce sera de la pure hypothèse, ce qui n'est pas vraiment compatible avec la phonétique (qui juge ce qu'on entend ou réalise). Nous ne connaissons de la phonologie latine que des systèmes d'opposition (on sait que tel ou tel son est plus ouvert que tel ou tel autre, mais rien qui permette de dire que c'est un [ɜ] ou un [ɞ] ou un [ɛ], etc).
- Dans ce cas, il n'y a pas besoin d'être très précis. On obient alors /a(ː)/, /e(ː)/, /i(ː)/, /o(ː)/, /u(ː)/ et /y(ː)/ (ce dernier pour les mots empruntés au grec, prononcé /u/ ou /i/ dans la langue populaire). Ici, les symboles /e/ et /o/ notent bien des voyelles fermées mais on ne sait pas de quelle aperture précise. On peut cependant penser, d'après l'évolution des voyelles dans les langues romanes, qu'une voyelle longue était plus fermée que sa contrepartie brève (/a/ restant cependant peu concerné). Dans ce cas : /a(ː)/, /ɛ/, /eː/, /ɪ/ (?) /iː/, /ɔ/, /oː/, /ʊ/ (?), /uː/. C'est cependant de la pure hypothèse.
- Pour les diphtongues classiques (en laissant de côté les diphtongues archaïques) : /ae̯/, /oe̯/, /au̯/.
- On sait d'autre part que :
- æ était réalisé plus ou moins /ɛː/ à partir du IIe s. avant notre ère mais /eː/ dans les campagnes (d'où quelques mots français issus de termes en æ qui ont subi le même traitement que s'il étaient issus de mots en ē : sæta → soie, alors que æ a normalement été confondu avec ĕ /ɛ/. Il faut noter le cas de Cæsar, que Claude a fait écrire Caisar et prononcer /kai̯sar/, prononciation pseudo-archaïsante qui n'est restée qu'en Germanie sous la forme kaisar, en gotique, puis Kaiser, etc. Le latin a conservé la graphie æ parce qu'il ne possédait de signe pour le phonème /ɛː/ ;
- œ est devenu /eː/ au IIe s. avant notre ère ;
- au est resté /au̯/ sauf dans le parler rural et quelques quelques mots ruraux où il est confondu avec ō (cauda → cōda ; pour les langues romanes, il faut partir de ce cōda et non de cauda pour expliquer les mots obtenus de cet étymon). Les langues romanes ne l'ont, du reste, pas toutes fait monophtonguer et si c'est le cas, c'est un développement qui leur est propre et non latin. Noter que au suivi, dans la syllabe d'après, d'un o ou d'un u passe à /a/ dès l'époque impériale, d'où August-{us|a} → Agust- → août, agosto, Aoste, etc.
- Il y aurait encore un grand nombre de détails notables, qui concernent cependant des points qui ne sont pas utiles pour la phonétique historique du français. J'espère avoir répondu à ta question. Vincent ✑ 16 jun 2004 à 20:04 (CEST)
- Sources : Phonétique historique du latin de Max Niedermann, La phonétique historique du latin dans le cadre des langues IE d'Albert Manet, Précis de phonétique historique de Noëlle Laborderie.
- P.-S. Quelques notions supplémentaires de phonétique latine dans Scansion, que j'ai écrit il y a peu.
- Ce petit texte ferait un bon début pour un article Prononciation du latin, non? Jyp 16 jun 2004 à 21:01 (CEST)
- Garder le système de Bourciez, je n'ai rien contre, c'est juste que je me demandais si, à part les étudiants en lettres, il était utilisé ailleurs (je ne l'ai jamais vu que dans mes cours de phonétique historique). Mais ça m'arrangerais de le garder effectivement, parce que j'ai encore du mal avec l'API.
- D'accord pour "phonologie", je confond(ai)s encore un peu phonétique et phonologie. Merci de m'avoir repris.
- Il suffit de ce souvenir que la phonétique est un cliché, un instantané de ce qu'on entend (ou de ce qu'on devrait entendre), indépendamment de la langue. C'est une description physique. La phonologie ne s'intéresse pas à la réalité des sons mais au système propre à une langue.
- En tout cas, merci beaucoup pour tes explications (et pour tes corrections sur mon début de texte - j'avais interrompu pour aller manger, d'où les crasses qui restaient).
- De rien. Je suis au contraire très heureux que quelqu'un d'autre s'intéresse aussi à la phonlogie.
- Il y a encore deux subtilités qui m'échappent. Parfois tu utilises « /eː/ » et d'autres fois « ē », alors est-ce que j'ai bien compris si je dis que le premier est en API, le second dans le système de Bourciez ?
- Exact. Mais le symbole [ē] existe en API : c'est un [e] prononcé sur un ton à registre moyen.
- Et s'ils sont tous les deux utilisés en API, quelle est la différence ? Et autre chose : pourquoi parfois isoler le phonème entre barres obliques et d'autre fois l'écrire en italique ? sur quoi fais-tu la différence ? Merci d'avance. --Serge(iNyar) 16 jun 2004 à 21:59 (CEST)
- Je suis un usage qui ne m'est pas propre mais que je trouve pratique : en italique tout autonyme (lettre citée en tant que lettre, symbole en tant que symbole, mot en tant que mot) et mot étranger (sauf si l'alphabet est différent). Or, le système de Bourciez n'est pas une transcription phonétique API : comme toute autre transcription, je la mets en italique. Le problème principal, c'est que les transcription phonologiques, entre barres obliques, n'utilisent pas un API strict. Par exemple, il est courant de se servir du macron pour les voyelles longues. On trouvera donc souvent /ē/ pour désigner /eː/. Vincent ✑ 17 jun 2004 à 00:26 (CEST)
Comité de pilotage
Salut Vincent. Ce petit mot pour te rappeler l'existence de l'important vote en cours pour le comité de pilotage de l'association. On a besoin de l'avis de tous ! Je t'invite à voter à : Wikipédia:Wikimédia francophone (Élection du comité de pilotage). Wiki-citoyen ! villy 26 jun 2004 à 14:09 (CEST)
Liste de tes images
Bonjour,
Un admin pourrait-il lancer une requête SQL pour recenser toutes les images que j'ai téléchargées sur le serveur, afin que je rende leur licence plus explicite ? Merci, Vincent ✑ 28 jun 2004 à 03:20 (CEST)
- À 07h30 heure française, impossible d'accèder à la base pour les requêtes SQL ... Je pensais que l'accès aux requêtes SQL était de retour, pas sur que ce soit le cas. Si quelqu'un a plus d'infos. Tipiac 28 jun 2004 à 07:28 (CEST)
- Pour l'instant, les administrateurs n'ont toujours pas accès aux requêtes SQL mais ça pourrait revenir. En attendant, trois solutions :
- demander a développeur de lancer la requête ;
- demander a quelqu'un qui a une version de Wikipédia récente chez lui de lancer la requête ;
- récupérer la liste complète des images et y chercher ton nom.
- A☮ineko ✍ 28 jun 2004 à 08:59 (CEST)
- Pour le n°3, c'cest surement plus rapide de consulter ses contributions en 500 par 500 --Pontauxchats Ier | ✉ 28 jun 2004 à 10:46 (CEST)
- Je pourrai essayer de faire le 2, mais pas avant ce soir au plus t^ot. Med 28 jun 2004 à 11:46 (CEST)
- Merci. Je vais attendre. Vincent ✑ 28 jun 2004 à 13:47 (CEST)
- Mission accomplie. Le résultat est sur ta page de discussion. Med 28 jun 2004 à 23:48 (CEST)
- Pour l'instant, les administrateurs n'ont toujours pas accès aux requêtes SQL mais ça pourrait revenir. En attendant, trois solutions :
Salut Vincent. J'ai fait une requête SQL sur le dernier dump pour avoir la liste de tes images. Si tu as d'autres demandes, n'hésite surtout pas. Med 28 jun 2004 à 23:46 (CEST)
select cur_title from cur where cur_namespace=6 and cur_user_text="Vincent Ramos" order by cur_title;
Accueil_trop_espace.png Allah_ligature.png Apex_latin.png Aqueduc_Peyrou.jpg Arabe_arch.png Aram_nabat_arabe_syriaque.png Bangla.png Barcelone_Parc_Guell_(1).JPG Barcelone_Parc_Guell_(10).jpg Barcelone_Parc_Guell_(11).jpg Barcelone_Parc_Guell_(2).JPG Barcelone_Parc_Guell_(3).JPG Barcelone_Parc_Guell_(4).JPG Barcelone_Parc_Guell_(5).JPG Barcelone_Parc_Guell_(6).JPG Barcelone_Parc_Guell_(7).JPG Barcelone_Parc_Guell_(8).JPG Barcelone_Parc_Guell_(9).JPG Boustrophedon.png Bémol.png Cap_min.png Capture_accueil_opera_linux_Vincent_Ramos.png Carte_Localisation_Région_France_Auvergne.png Chuan_arch.png Chuan_sigil.png Circonflexes_de_Sylvius.png Circulus_super_capite.png Comedie.JPG Comp_arabe_hebreu_etc.png Comp_arabe_hebreu_etc2.png Compa.jpg Coulees_du_Vesuve.jpg Coupe_oeil.jpg Cour-Heidelberg.jpg Cyrillique_cursif.png Cyrillique_serbe_russe.PNG D_r_nabat_syriaque.png Dasus.png Deflechi_lao.png Deflechi_wang.png Dièse.png Do_maj.mid Drole_de_truc_qui_se_passe.png Dvorak.jpg Emprunt_lai.png Emprunt_wan.png Exemple_gotique.png Exemples_bicamerales.png Extrait_du_dico_de_styles_caligraphiques.png Gotique.png Graffiti_politique_de_Pompei.jpg Gui_arch.png Gui_sigil.png Gujarati.png Hanzi_image.png Hebreu_hist_arabe.png Hindi.png I_longa.png Immeuble.jpg Imprime_shuo.png Innocent.jpg Innocent_petit.jpg Inscription_sideen.jpg Italique_cursive.png Italique_oblique.png Kryptonite.png Kryptonite2.png Ligature_arabe_lam_alif.png Ligature_grecque_kai.png Ligatures_arabes_optionnelles.png Ligatures_latines_courantes.png Lithuania_coa.png Logo_ecriture_Japon.png Logo_sinogrammes.png Long_arch.png Long_sigil.png Léguman.jpg Ma_arch.png Ma_sigil.png Manuscrit_shuo.png Manuscrit_shuo2.png Megatokyo-strip381_s.png Mu_arch.png Mu_sigil.png Nepali.png Niao_arch.png Niao_sigil.png Nuu_arch.png Nuu_sigil.png Om_manipadme_hum_sanskrit.png Panjabi.png Pavillon_Peyrou.jpg Pavillon_Peyrou2.jpg Peyrou.jpg Phon_gotique.png Phon_gotique2.png Phon_gotique3.png Phrase_sanskrite.png Psilon.png Punctum superscriptum.svg Radical_de_sinogramme_ma1.png Radical_nuu_hao.png Radical_nuu_jie.png Radical_nuu_ma.png Radical_nuu_qie.png Radical_nuu_ta.png Radical_nuu_xing.png Radicaux_de_luan.png Religion_grecque.png Ren_arch.png Ren_sigil.png Ri_arch.png Ri_sigil.png Ridicule.jpg Rouge2.jpg Rue.JPG Sanskrit.png Sanskrit_rate.png Shan_arch.png Shan_sigil.png Shui_arch.png Shui_sigil.png Sinogrammes_style_courant.png Sinogrammes_style_regulier.png Sinogrammes_style_scribes.png Sinogrammes_style_sigillaire.png Soutra_du_diamant.png Soutra_du_diamant_ouvert.png Svastika.png Tableau_de_radicaux_en_composition.png Tableau_des_diacritiques_latins.png Tamil.png Telugu.png Test_Unicode_API.png Test_Unicode_ChinoisSimpl.png Test_Unicode_ChinoisTrad.png Test_Unicode_Grec.png Test_Unicode_Grec2.png Test_Unicode_latin.png Test_arabe2.png Test_arabe3.png Test_arabe4.png Test_arabe6.png Test_arabe7.png Test_arabe8.png Texte_sino_japonais.png Urdu.png Variantes_contextuelles_en_arabe.png Variantes_contextuelles_en_arabe2.png Variantes_contextuelles_hebraiques.png Variantes_contextuelles_latines.png Variantes_contextuelles_latines2.png Variantes_contextuelles_latines3.png Vincent_Ramos.jpg Voir_aussi.png Voyelles_monotoniques.png Vue_Carre_St-Anne.jpg Vue_du_Vesuve.jpg Wikiarabe.png Yu_arch.png Yu_sigil.png Yue_arch.png Yue_sigil.png Zhu_arch.png Zhu_sigil.png Zi_arch.png Zi_sigil.png
Je vois que tu as déjà eu ta reponse :o) La prochaine fois, tu peux utiliser la page http://meta.wikipedia.org/wiki/Requests_for_queries. Tiens, j'ai passé une p'tite macro sur la liste ci-dessus pour y ajouter des liens et une vignette. Si ca peux servir... A☮ineko ✍ 29 jun 2004 à 05:33 (CEST)
- image:Accueil_trop_espace.png Fichier:Accueil trop espace.png
- image:Allah_ligature.png Fichier:Allah ligature.png
- image:Apex_latin.png

- image:Aqueduc_Peyrou.jpg

- image:Arabe_arch.png

- image:Aram_nabat_arabe_syriaque.png

- image:Bangla.png

- image:Barcelone_Parc_Guell_(1).JPG

- image:Barcelone_Parc_Guell_(10).jpg

- image:Barcelone_Parc_Guell_(11).jpg

- image:Barcelone_Parc_Guell_(2).JPG

- image:Barcelone_Parc_Guell_(3).JPG

- image:Barcelone_Parc_Guell_(4).JPG

- image:Barcelone_Parc_Guell_(5).JPG

- image:Barcelone_Parc_Guell_(6).JPG

- image:Barcelone_Parc_Guell_(7).JPG

- image:Barcelone_Parc_Guell_(8).JPG

- image:Barcelone_Parc_Guell_(9).JPG

- image:Boustrophedon Greek.png

- image:Bémol.png

- image:Cap_min.png

- image:Capture_accueil_opera_linux_Vincent_Ramos.png Fichier:Capture accueil opera linux Vincent Ramos.png
- image:Carte_Localisation_Région_France_Auvergne.png Fichier:Carte Localisation Région France Auvergne.png
- image:Chuan_arch.png

- image:Chuan_sigil.png
- image:Circonflexes_de_Sylvius.png

- image:Circulus_super_capite.png

- image:Comedie.JPG

- image:Comp_arabe_hebreu_etc.png

- image:Comp_arabe_hebreu_etc2.png

- image:Compa.jpg

- image:Coulees_du_Vesuve.jpg

- image:Coupe_oeil.jpg

- image:Cour-Heidelberg.jpg

- image:Cyrillique_cursif.png

- image:Cyrillique_serbe_russe.PNG

- image:D_r_nabat_syriaque.png

- image:Dasus.png
- image:Deflechi_lao.png

- image:Deflechi_wang.png

- image:Dièse.png

- image:Do_maj.mid
- image:Drole_de_truc_qui_se_passe.png Fichier:Drole de truc qui se passe.png
- image:Dvorak.jpg

- image:Emprunt_lai.png

- image:Emprunt_wan.png
- image:Exemple_gotique.png

- image:Exemples_bicamerales.png

- image:Extrait_du_dico_de_styles_caligraphiques.png Fichier:Extrait du dico de styles caligraphiques.png
- image:Gotique.png

- image:Graffiti_politique_de_Pompei.jpg

- image:Gui_arch.png

- image:Gui_sigil.png

- image:Gujarati.png

- image:Hanzi_image.png

- image:Hebreu_hist_arabe.png

- image:Hindi.png

- image:I_longa.png

- image:Immeuble.jpg

- image:Imprime_shuo.png

- image:Innocent.jpg

- image:Innocent_petit.jpg Fichier:Innocent petit.jpg
- image:Inscription_sideen.jpg

- image:Italique_cursive.png

- image:Italique_oblique.png

- image:Kryptonite.png Fichier:Kryptonite.png
- image:Kryptonite2.png Fichier:Kryptonite2.png
- image:Ligature_arabe_lam_alif.png

- image:Ligature_grecque_kai.png
- image:Ligatures_arabes_optionnelles.png

- image:Ligatures_latines_courantes.png

- image:Lithuania_coa.png Fichier:Lithuania coa.png
- image:Logo_ecriture_Japon.png

- image:Logo_sinogrammes.png

- image:Long_arch.png

- image:Long_sigil.png

- image:Léguman.jpg

- image:Ma_arch.png

- image:Ma_sigil.png

- image:Manuscrit_shuo.png

- image:Manuscrit_shuo2.png

- image:Megatokyo-strip381_s.png Fichier:Megatokyo-strip381 s.png
- image:Mu_arch.png

- image:Mu_sigil.png

- image:Nepali.png

- image:Niao_arch.png

- image:Niao_sigil.png

- image:Nuu_arch.png Fichier:Nuu arch.png
- image:Nuu_sigil.png

- image:Om_manipadme_hum_sanskrit.png

- image:Panjabi.png

- image:Pavillon_Peyrou.jpg

- image:Pavillon_Peyrou2.jpg Fichier:Pavillon Peyrou2.jpg
- image:Peyrou.jpg

- image:Phon_gotique.png

- image:Phon_gotique2.png Fichier:Phon gotique2.png
- image:Phon_gotique3.png Fichier:Phon gotique3.png
- image:Phrase_sanskrite.png

- image:Psilon.png

- image:Punctum superscriptum.svg

- image:Radical_de_sinogramme_ma1.png

- image:Radical_nuu_hao.png

- image:Radical_nuu_jie.png

- image:Radical_nuu_ma.png

- image:Radical_nuu_qie.png

- image:Radical_nuu_ta.png

- image:Radical_nuu_xing.png

- image:Radicaux_de_luan.png

- image:Religion_grecque.png Fichier:Religion grecque.png
- image:Ren_arch.png

- image:Ren_sigil.png

- image:Ri_arch.png

- image:Ri_sigil.png

- image:Ridicule.jpg Fichier:Ridicule.jpg
- image:Rouge2.jpg Fichier:Rouge2.jpg
- image:Rue.JPG Fichier:Rue.JPG
- image:Sanskrit.png
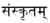
- image:Sanskrit_rate.png

- image:Shan_arch.png

- image:Shan_sigil.png

- image:Shui_arch.png
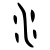
- image:Shui_sigil.png
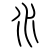
- image:Sinogrammes_style_courant.png

- image:Sinogrammes_style_regulier.png

- image:Sinogrammes_style_scribes.png

- image:Sinogrammes_style_sigillaire.png Fichier:Sinogrammes style sigillaire.png
- image:Soutra_du_diamant.png

- image:Soutra_du_diamant_ouvert.png

- image:Svastika.png

- image:Tableau_de_radicaux_en_composition.png

- image:Tableau_des_diacritiques_latins.png

- image:Tamil.png

- image:Telugu.png

- image:Test_Unicode_API.png

- image:Test_Unicode_ChinoisSimpl.png

- image:Test_Unicode_ChinoisTrad.png

- image:Test_Unicode_Grec.png

- image:Test_Unicode_Grec2.png

- image:Test_Unicode_latin.png

- image:Test_arabe2.png

- image:Test_arabe3.png

- image:Test_arabe4.png

- image:Test_arabe6.png

- image:Test_arabe7.png

- image:Test_arabe8.png

- image:Texte_sino_japonais.png

- image:Urdu.png

- image:Variantes_contextuelles_en_arabe.png

- image:Variantes_contextuelles_en_arabe2.png

- image:Variantes_contextuelles_hebraiques.png

- image:Variantes_contextuelles_latines.png

- image:Variantes_contextuelles_latines2.png

- image:Variantes_contextuelles_latines3.png

- image:Vincent_Ramos.jpg Fichier:Vincent Ramos.jpg
- image:Voir_aussi.png Fichier:Voir aussi.png
- image:Voyelles_monotoniques.png

- image:Vue_Carre_St-Anne.jpg

- image:Vue_du_Vesuve.jpg

- image:Wikiarabe.png Fichier:Wikiarabe.png
- image:Yu_arch.png

- image:Yu_sigil.png

- image:Yue_arch.png
- image:Yue_sigil.png

- image:Zhu_arch.png

- image:Zhu_sigil.png

- image:Zi_arch.png
- image:Zi_sigil.png

.jpg)
.JPG)
.JPG)
.JPG)
.JPG)




















































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.JPG){kind=link}
.jpg){kind=link}
.JPG){kind=link}
.JPG){kind=link}
.JPG){kind=link}
.JPG){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bon bein je suis tombé sur certaines de tes images et y ai mis licenceInconnue, mais maintenant que tu as la liste, ça devrait changer donc je te les liste pas la. Bonne chance pour les licences et merci ! Tipiac 29 jun 2004 à 12:25 (CEST)
Roby : Cher Vincent, je partage ton avis en ce qui concerne la préservation de la mémoire et donc la nécessité, lors d'une destruction, de prendre des avis compétents et de ne pas agir d'autorité. Surtout lorsqu'on détient un pouvoir et lorsqu'un conflit peut rendre cette manœuvre suspecte. C'est la raison pour laquelle j'ai cru bon d'étudier, de traduire librement et de commenter la pratique anglophone sur laquelle tu avais pointé un lien : en:Wikipedia:User_page. Mon anglais et mon expérience wikipédienne sont insuffisants pour traiter honnêtement les 2 derniers points de cet article, ceux qui parlent précisément des points que tu soulevais. Pourrais-tu compléter donc Wikipédia:Pages personnelles ? Merci d'avance.
La mise au point concernant la paternité du paragraphe Pages personnelles que tu avais, semble-t-il, oublié de signer, ne visait donc pas à contester ton intervention mais à en contester la paternité. Wikinaute de quelques mois, je te trouvais en effet que la méprise d'Anthère — en m'attribuant la velléité de changer unilatéralement les règles régissant le bon usage des pouvoirs d'administrateur — me taillait le costume d'un présomptueux ridicule.
Amicalement, Roby 18 avr 2004 à 08:39 (CEST)
- Ok, message reçu.
Galicien
Hello. Une page a été créée sur Galicien par un non francophone. j'ai francisé le 1er §, mais je n'y connais rien et j'ai surtout pas compris la suite... ;o) Peut-être y arriverais-tu mieux que moi. si oui merci, sinon tant pis, j'y arriverai bien un jour. :o) a+ --Pontauxchats Ier|@ 18 avr 2004 à 10:19 (CEST)
- C'est gentil de penser à moi mais je n'ai vraiment plus le temps. Bon, je la garde affichée pour faire un tour quand l'occasion se présente. Vincent (discuter) 18 avr 2004 à 12:24 (CEST)
J'ai revu cet article et l'ai rendu compréhensible Fred091 18 avr 2004 à 12:52 (CEST)
- Merci.
J'ai ajouté la liste des liens (28 mai 2004).
Cher Vincent. Merci beaucoup pour ton mail; Cela fait deux jours que j'y pense :-) J'y réfléchi, j'y réfléchi et je pense qu'il va me donner une idée :-) Je te répondrai plus tard quand cela sera mûr :-) ant
- Il n'appelait pas forcément de réponse. Prends ton temps ;-) Vincent (discuter) 20 avr 2004 à 18:48 (CEST)
Qu'est-ce qu'un article Wiki ?
Déplacé depuis Bistro car lien rouge => non pertinent, ou à corriger & remettre sur le Bistro :) Ryo 23 avr 2004 à 10:58 (CEST)
Note : Le texte ci-dessous a été déplacé depuis le Bistro de Wikipédia pour alléger cette page qui ne cesse de s'allonger. Texte déplacé par : Vincent (discuter) 17 avr 2004 à 12:44 (CEST) dans Wikipédia:Le Bistro/Qu'est-ce qu'un article de Wikipédia ?
- Lien corrigé (la faute à l'insécable...).Vincent (discuter) 28 avr 2004 à 07:01 (CEST)
Chinese Translation
Your question answered : zh:Wikipedia:互助客栈 --Cylauj 25 avr 2004 à 20:48 (CEST)
- Thanks. Vincent (discuter) 25 avr 2004 à 21:00 (CEST)
lettrines des articles de linguistique
Dans de nombreux articles du domaines [linguistique] (y compris [écriture] et [langue]), une lettrine en image indique le sujet en VO, suivie, quelques mots plus loins, de la copie en unicode; par exemple « संस्कृतम् » pour [sanskrit]. ([Langues de l'Inde])
- dans sinogramme, Image:Hanzi image.png n'a pas de transcription en textuelle qui suive
- Le terme est donné en texte brut deux lignes plus bas. De toute façon, je viens de retirer l'image, devenue inutile.
- si quelqu'un souhaite remplacer ces lettrines en image par du texte, voici du code html + css : संस्कृतम्
- Je n'en vois pas trop l'intérêt, en fatit. Les écritures indiennes sont rarement correctement prises en charge par les navigateurs actuels. À supposer qu'un lecteur consultant cette page ait déjà les polices nécessaires installées dans son système, il y a fort à parier qu'il verra n'importe quoi, comme . C'est le cas pour moi actuellement (l'image est une copie d'écran de ce que je vois). Comme je sais lire la devanāgarī et me débrouille avec les autres semi-syllabaires de l'Inde, je corrige de moi-même ( ). Je préfère qu'il reste une image pour éviter, dans l'état actuel des technologies, de produire une lettrine fausse. Vincent (discuter) 26 avr 2004 à 00:38 (CEST)
- Excellente raison. (28 mai 2004)
MediaWiki langues IE
Salut Vincent, j'ai renoncé pour le moment à intégrer Modèle:LanguesIE à Wikipédia:Palettes de navigation/Linguistique : penses-tu que l'on pourrait subdiviser ce mediawiki en d'autres de tailles plus restreintes sous forme de tableaux ? ; Amaury 27 avr 2004 à 00:47 (CEST)
- Oui, j'y pense mais tous les problèmes n'ont pas été résolus, à savoir, principalement : où place-t-on les listes de langues ? Dans des articles à part ? Dans les articles de langues ? Il y a dans mes archives des discussions longues à ce sujet. Vincent (discuter) 27 avr 2004 à 06:43 (CEST)
- Je viens de procéder à un essai dans le bac à sable sous le titre Test langues IE, tes commentaires sont bienvenus, bien entendu. ; Amaury 28 avr 2004 à 01:37 (CEST)
- Cela ne semble pas mal. Mais le problème est tout autre, en fait. Vois dans Discussion Utilisateur:Vincent Ramos/Archives5 les débats possibles. Vincent (discuter) 28 avr 2004 à 15:53 (CEST)
- Il est vrai que beaucoup d'aspects sont à prendre en compte : que dirais-tu de lancer un espace de réflexion et d'action, sous la forme d'un projet, dédié à la question du langage ? ; Amaury 28 avr 2004 à 16:51 (CEST)
- En fait, actuellement je suis lancé dans un projet sur les sinogrammes qui me prend pas mal de temps. J'ai peur, si on lance une réflexion sur le sujet, de ne pas trop avoir la possibilité de m'y investir. Mais l'idée reste bonne. Vincent | 討論 28 avr 2004 à 17:43 (CEST)
- Il est vrai que beaucoup d'aspects sont à prendre en compte : que dirais-tu de lancer un espace de réflexion et d'action, sous la forme d'un projet, dédié à la question du langage ? ; Amaury 28 avr 2004 à 16:51 (CEST)
des modifications d'articles de langues
- Dans [MediaWiki:Sinogramme] :
- Le code CSS « border: inset purple; » ne prend pas de virgule entre inset et purple. La brodure violet apparait à présent.
- Il doit y avoir une plus grande tolérance à l'erreur de mon navigateur, qui m'affichait correctement la bordure. Et dire que j'ai participé à la relecture de la traduction officielle de documents concernant le CSS2 du W3C... Bravo la virgule.
- dans la norme CSS 2, des valeurs peuvent être énumérées et séparés par des virgules pour voice-family, font-family, et d'autres propriété.
- J'ai ajouté « width: 12em; » et supprimé les retours à la lignes dans les textes de descriptions des liens. Je ne sais pas si cela est correctement interprété par tous les logiciels
- Cela marche très bien pour moi.
- [lituanien]
- J'ai supprimé dans [vietnamien] le tableau (importé de en:) de ce que les participants de :en: doivent considérer comme les informations principales pour une langue. Je ne l'ai pas fait pour [lituanien], dans lequel la tableau a été ajouté par Utilisateur:Robin_Hood. Je ne suis pas sûr que ce soit ici le meilleur endroit pour en discuter.
- Vous avez bien fait. Je crois cependant qu'il va falloir lancer une concertation pour les langues afin qu'on trouve un modus operandi commun. Vincent | 討論 29 avr 2004 à 18:21 (CEST)
- Le tableau a été ajouté (apres plusieurs modifications) dans letton lituanien polonais sudovien vieux prussien
- Les tableaux sont insérés pour servir de référence rapide, et de nombreuses modifications ont été apportées, je crois, pour satisfaire aux divers types de navigateurs. Faudrait voir s'ils causent encore des problèmes, car même si j'ai inité le mouvement, j'y tiens pas mordicus. Robin des Bois 5 mai 2004 à 03:44 (CEST)
- En fait, nous en sommes encore à nous demander quelle est la meilleure solution. Il va falloire lancer une concertation sur le sujet car chaque article de langue a sa propre logique. Vincent | 討論 5 mai 2004 à 07:09 (CEST)
- D'accord avec toi, faudrait concensus. Mais qui va lancer la concertation? Pourrais-tu me tenir au courant? Robin des Bois 5 mai 2004 à 08:28 (CEST)
- Ben les personnes qui participent aux modifications des articlesde langue et de linguistique.
- D'accord avec toi, faudrait concensus. Mais qui va lancer la concertation? Pourrais-tu me tenir au courant? Robin des Bois 5 mai 2004 à 08:28 (CEST)
- En fait, nous en sommes encore à nous demander quelle est la meilleure solution. Il va falloire lancer une concertation sur le sujet car chaque article de langue a sa propre logique. Vincent | 討論 5 mai 2004 à 07:09 (CEST)
- Les tableaux sont insérés pour servir de référence rapide, et de nombreuses modifications ont été apportées, je crois, pour satisfaire aux divers types de navigateurs. Faudrait voir s'ils causent encore des problèmes, car même si j'ai inité le mouvement, j'y tiens pas mordicus. Robin des Bois 5 mai 2004 à 03:44 (CEST)
- Message à cette personne : pourquoi vouloir couper en deux, et le mettre deux fois, le lien [langues indo-européennes] ?
- Pas d'autre annulation de ma modification inverse dans le tableau
- Je vous ai posé beaucoup de question dans cette page (voir archives 4, 5 et 6), et vous m'avez répondu à la plupart. Je n'ai pas répondu, car la plupart de vos réponses m'ont fort satisfairte, confirmant ou contredisant ce que je pensais, mais m'étant profitables. Je tiens donc à vous remercier chaleureusement.
- [langue naturelle]] Je vous avais posé une question sur cet article :)
Vous l'avez relu plus tard, et avez corrigé. Cela amène plutôt à en sourire. Si vous préférez ne pas supprimer l'article, vouci ma modeste contribution :
« {msg:Ebauche}
Une [langue naturelle] désigne en [linguistique] le contraire d'une [langue construite].
[en:Natural language] [eo:Natura lingvo] [es:Lengua natural] [sw:Lugha Asilia] »
- Franchement, pour cette histoire de langue naturelle, je ne comprends pas comment j'ai laissé passer un tel truc ! Bien, votre bouchon et heureux d'avoir répondu à vos questions. Vincent | 討論 30 avr 2004 à 20:20 (CEST)
- Dans Langues par famille :
- Préambule
supprimer le troisième paragraphe ?
- Il ne me semble pas très important non plus. Vincent | 討論 5 mai 2004 à 07:09 (CEST)
- Je le fusionne avec le deuxième
- langues indo-européennes, langues germaniques, langues scandinaves :
supprimer la séparation entre sous-groupe occidental et sous-groupe oriental ? Le norvégien bokmål fait-il parti du sous-groupe occidental ?
- Les sous-groupes oriental / occidental sont bien reconnus. Le bokmål étant d'origine danoise, il fait bien partie du groupe occidental (voyez là). Vincent | 討論 5 mai 2004 à 07:09 (CEST)
- Vous voulez dire le sous groupe oriental ?
J'ai mis le bokmål dans le sous groupe oriental. C'est juste ? (28 mai 2004)
Langues balto-slaves
Bonjour Vincent. Comme tu sembles bien t'y connaître sur le sujet, j'ai besoin de tes lumières. J'ai constaté que dans la plupart des références sur Wikipédié, on place les langues baltes et les langues slaves dans le même groupe balto-slave. Pourtant, Je crois bien que depuis des années, les linguistes s'étaient entendus pour en faire deux groupes distincts malgré leur proche parenté. Après de nombreuses recherches sur les encyclopédies du web et en bibliothèque, j'ai trouvé bien peu de références appuyant cette union. Comme tu as dû le voir, j'ai fait plusieurs contributions dans ces langues et je voudrais éviter tout conflit d'édition s'il existe déjà un consensus. Robin des Bois 5 mai 2004 à 03:44 (CEST)~
- Pour moi, elles sont liées. Mais je suis tribuataire d'un enseignement linguistique qui peut parfois dater un peu. Je ne suis pas spécialiste de ce sujet mais les auteurs que je respectent par ailleurs pour leur bon sens les classent ensemble. D'autres, que je connais moins mais sont plus récents, les séparent. Je pense que les séparer est plus consensuel. Vincent | 討論 5 mai 2004 à 07:09 (CEST)
- Larousse et Glolier, pour ne nommer que les plus simples et répandus, les séparent. Je me propose pour modifier les articles que je rencontre pour faire cet ajustement, tout en mentionnant, si le contexte l'exige, que certaines écoles les considèrent comme un seul groupe. Est-ce un bonne idée? (En passant, j'ai laissé un petit mot à ton attention dans la page Discuter:Chaos (mythologie).) Robin des Bois 5 mai 2004 à 08:23 (CEST)
- (Si on convien de supprimer la page [balto-slave] et ses mentions dans d'autrse page) Techniquement, il suffit de demander les pages liées à [balto-slave], pour trouver les pages ayant un lien vers elle, et pourvoir enlever ces liens.
- Ouais, mais je vais attendre d'avoir les références exactes les plus récentes pour appuyer ce classement avant de tout changer. Robin des Bois 5 mai 2004 à 21:12 (CEST)
- Il faudrait demander dans news:sci.lang. Vincent | 討論 5 mai 2004 à 21:19 (CEST)
- Ouais, mais je vais attendre d'avoir les références exactes les plus récentes pour appuyer ce classement avant de tout changer. Robin des Bois 5 mai 2004 à 21:12 (CEST)
indiquer certaines tailles de polices
Pour Wikipédia:Test Unicode arabe et Wikipédia:Unicode/Test devanâgarî, pourriez vous indiquer quelle taille de police vous utilisates pour les images, afin de remplacer les « font size="+8" », qui sont sont imprécis et dépandent de la taille de base, par « font style="font-size: 30px;" »; pour que le texte et les images aient la même taille à l'affichage.
- Oups, je n'en sais trop rien... Vincent | 討論 3 mai 2004 à 14:48 (CEST)
- Tant pis. Ce n'est pas grave. on fera par approximations.
Note : le texte ci-dessous a été déplacé depuis le Bistro de Wikipédia. Ryo 4 mai 2004 à 09:58 (CEST)
Enthousiasme
Toute modestie gardée [sic], je suis très fier de moi : après avoir lutté avec Gimp, j'ai réussi à obtenir ce que je cherchais et que vous pouvez voir dans Radical (sinogramme).
Juste pour le dire, car je suis content. Vincent | 討論 29 avr 2004 à 19:22 (CEST)
- Superbe! Déjà que j'ai mis du temps à comprendre tracer une pauvre ellipse avec Gimp ... alors là! ;) Med 29 avr 2004 à 19:29 (CEST)
- Félicitations pour ton article VR. De belles images ! --youssef 29 avr 2004 à 19:37 (CEST)
- Absolument magnifique ! villy 29 avr 2004 à 19:42 (CEST)
- Un trés bel article, rajouté au panthéon des articles. Greudin (Discuter)
- En fait la mise au panthéon des articles nécessite un vote préalable :| Treanna 30 avr 2004 à 11:01 (CEST)
- Ah oui m*rde j'avais pas lu, je le déplace. Votez sur Proposition articles de qualité Greudin (Discuter)
ϐ vs. β
Salut, juste une petite remarque pour ϐ/β : il me semble que ϐ est une particularité franco-française, et que les autres pays mettent β partout, quelque soit la position dans le mot. Est-ce que ça te dit quelque chose ? D'ailleurs, il n'y a pas d'entité HTML pour ϐ (GREEK SYMBOL BETA), c'est pas une preuve ça ? ;-)
Pour les Synœcies, le Liddell-Scott accentue συνοίκια et non συνοικία. Jastrow 4 mai 2004 à 20:58 (CEST)
- Pour β/ϐ, j'ai écrit un paragraphe dans Variante contextuelle. C'est bien une particularité des éditions francophones. Je le défendrai donc bec et ongles car les bonnes éditions, Budé par exemple, l'utilisent toujours (bien que ce soit une sottise qu'aucune tradition ne peut justifier ; j'ai sous les yeux un fac simile d'une édition princeps française de poèmes en grec du XVIe siècle : le ϐ n'est bien sûr pas employé...).
- Pour les Synœcies, je n'ai regardé que le Bailly, qui ne connaît pas συνοίκια. Je n'ai pas le LS chez moi mais le consulte sur Perseus. Pour l'instant, il n'est pas accessible, mais tout à l'heure j'y ai fait un tour et il connaissait bien συνοικία. Je n'ai pas regardé συνοίκια, en revanche. J'essaierai de nouveau plus tard.
- Heureux de trouver un helléniste ici, Vincent | 討論 4 mai 2004 à 21:22 (CEST)
- Sinon, c'est un peu déroutant ce que tu dis pour le LS, que je consulte moi aussi via Perseus, donnerait-il les deux ? Le Lejeune va-t-il devoir départager les choses ?
- J'ai résolu l'affaire. En fait, si συνοίκια est possible, il faut que le dernier α soit bref : συνοίκιᾰ. Or, cette forme ne peut être que celle de l'adjectif au neutre pluriel (dont la désinence directe est un -ᾰ). Donc, c'est l'adjectif : συνοίκια (ἱερά), « (cérémonies) synœciennes ». Le nom, quant à lui, est bien συνοικία, avec -ᾱ final. Liddel le prouve :
- Or, vu la fréquence (deux attestations pour συνοίκιᾰ, soixante-douze pour συνοικίᾱ), je pense qu'il vaut mieux utiliser le nom, de même qu'on ne dit pas les « (cérémonies) panathénéennes » mais les Panathénées.
- Ah, et j'avoue : je suis quand même plus beaucoup plus latiniste qu'hélléniste. Comme Des Esseintes, je n'ai jamais pu accrocher le grec (ou le grec ne m'accroche pas, au choix), bien que je m'intéresse beaucoup à la civilisation et à l'art grecs... Jastrow 4 mai 2004 à 21:46 (CEST)
- Dommage... Je ne peux pas en dire autant car la langue grecque me plaît autant, si ce n'est plus, que sa civilisation. Content cependant d'avoir papoté de grec. Bonne continuation, en tout cas, Vincent | 討論 4 mai 2004 à 23:05 (CEST)
- Sinon, c'est un peu déroutant ce que tu dis pour le LS, que je consulte moi aussi via Perseus, donnerait-il les deux ? Le Lejeune va-t-il devoir départager les choses ?
- « Les bonnes éditions » : il y en a d'autres en France ? :)
- Oui, malheureuseument. Par exemple les Fables d'Ésope, édition bilingue traduite par Daniel Loayza chez GF-Flammarion : les β médians ne sont pas des ϐ.
- « Les bonnes éditions » : il y en a d'autres en France ? :)
- Merci de confirmer, je n'avais pas d'édition étrangère en grec chez moi pour ce faire.
- Tu n'as jamais travaillé sur des Loeb ? Ce que j'aime bien chez eux c'est que les textes papyrologiques utilisent c et non σ/ς (ce qui évite de devoir trancher : il n'est pas toujours aisé, dans un texte papyrologique, de savoir si un sigma est en fin de mot ou non).
- Je n'ai des Loeb qu'en latin (moins chers que les Budés, même en import)...
- Tu n'as jamais travaillé sur des Loeb ? Ce que j'aime bien chez eux c'est que les textes papyrologiques utilisent c et non σ/ς (ce qui évite de devoir trancher : il n'est pas toujours aisé, dans un texte papyrologique, de savoir si un sigma est en fin de mot ou non).
- Merci de confirmer, je n'avais pas d'édition étrangère en grec chez moi pour ce faire.
- Je vais essayer de mettre des ϐ médians, mais bon il faut bien avouer que ce serait plus facile avec un &varbeta;...
- Comment entres-tu le texte grec ? Sous Linux/Unix/BeOs, inclure le ϐ dans le clavier est très simple. Avec Windows, je sais aussi comment faire. Si tu es sous Mac non OS/X, désolé...
- Je suis sous FreeBSD, je n'ai pas encore tout passé en Unicode donc c'est tapé à la mimine, avec des entités HTML. Je copipaste depuis des tables Unicode les caractères accentués. Si tu as une méthode pour entrer le texte directement, ça m'intéresse.
- L'ami qui a amélioré ma disposition clavier pour entrer du grec polytonique est justement sous FreeBSD. Il devrait pouvoir t'aider. Quelle est ta locale ? Utf-8 ? Entre temps, je viens de lui envoyer un courriel. Vincent | 討論 5 mai 2004 à 06:48 (CEST)
- Justement, ma locale est bêtement fr_FR.ISO8859-1... Jastrow 5 mai 2004 à 13:11 (CEST)
- Tu dois pouvoir lancer une application en passant une autre locale, non ? Bon, j'attends la réponse de mon ami. Vincent | 討論 5 mai 2004 à 14:37 (CEST)
- Justement, ma locale est bêtement fr_FR.ISO8859-1... Jastrow 5 mai 2004 à 13:11 (CEST)
- L'ami qui a amélioré ma disposition clavier pour entrer du grec polytonique est justement sous FreeBSD. Il devrait pouvoir t'aider. Quelle est ta locale ? Utf-8 ? Entre temps, je viens de lui envoyer un courriel. Vincent | 討論 5 mai 2004 à 06:48 (CEST)
- Je suis sous FreeBSD, je n'ai pas encore tout passé en Unicode donc c'est tapé à la mimine, avec des entités HTML. Je copipaste depuis des tables Unicode les caractères accentués. Si tu as une méthode pour entrer le texte directement, ça m'intéresse.
- Comment entres-tu le texte grec ? Sous Linux/Unix/BeOs, inclure le ϐ dans le clavier est très simple. Avec Windows, je sais aussi comment faire. Si tu es sous Mac non OS/X, désolé...
- Je vais essayer de mettre des ϐ médians, mais bon il faut bien avouer que ce serait plus facile avec un &varbeta;...
Caractères spéciaux
À propos des caractères bizarres sous X11+Unix, j'utilise xmodmap (paraît-il obsolète avec X4.3 mais il marche quand même), très pratique. J'utilise AltGr pour obtenir π, œ, € ou «. Je n'ai pas encore trouvé le code pour l'espace insécable mais ça me travaille. ℓisllk★✉ 5 mai 2004 à 15:13 (CEST)
- Je n'utilise pas xmodmap, mais par défaut sous Mandrake, l'espace insécable s'obtient par « compose + espace + espace » Med 5 mai 2004 à 15:21 (CEST)
- Ayé, j'ai trouvé : « keycode 65 = space nobreakspace » fait que shift+espace donne l'espace insécable. Il suffit de lire /usr/X11R6/include/X11/keysymdef.h sur ma Sarge, d'y lire le nom du caractère et d'enlever le préfixe XK_ en gardant la casse. En en plus, les codes unicode hexadécimaux sont placés en regard. ℓisllk★✉ 5 mai 2004 à 15:41 (CEST)
- Quant à moi, j'utilise setxkbmap pour charger au démarrage une table de /usr/X11R6/lib/X11/xkb/symbols/pc/ que j'ai modifiée à la main, comprenant l'espace insécable et plein d'autres trucs, ainsi que la possibilité d'appeler une autre table, celle du grec polytonique. Je lance le tout avec -layout fr,el-poly -option "grp:shift_toggle", qui appelle les tables fr et el-poly, cette dernière m'ayant été tricotée à la main par un ami qui l'a publiée sous license BSD. Vincent | 討論
- Ça-y-est, tu es un vrai geek ! ℓisllk★✉ 5 mai 2004 à 16:01 (CEST)
- Eh oui... Remarque, c'est bien l'image que je donnais de moi avant à mon entourage : toujours devant mon clavier, c'est moi qu'on appelle pour dépanner les PC (voire un Mac, une fois !) des uns et des autres, je passe, dans mon milieu socio-professionnel, pour un spécialiste (alors que je pense plutôt que ma connaissance de l'informatique me permet de mesurer mes lacunes). Depuis mon passage à Linux, c'est devenu pire : la preuve, l'administrateur réseau de mon collège (une soixantaine de postes) m'a fourni tous les droits pour le seconder (sous NT...). Et tous de me faire confiance. Bon, reconnaissons-le, je suis une sorte de geek. Vincent | 討論 5 mai 2004 à 17:43 (CEST)
- Pareil sous Unix, je mesure l'étendue de mon ignorance en particulier sur les réseaux, et par extension un peu partout et surtout sur mon domaine de compétence : les maths. Je connais plutôt Linux (j'y bidouille), je suis un ignare sur Windows et pourtant on me qualifie de balaise en info. La bonne blague. Qu'on me donne à gérer le système du bahut et on va rire. ℓisllk★✉ 5 mai 2004 à 18:02 (CEST)
- Les mots Unix ou Linux sont lâchés : on crie au génie informatique. On ne me voit pas pester contre ces #%☁☗☠☹!!! de messages d'erreur incompréhensibles ! Vincent | 討論 5 mai 2004 à 18:26 (CEST)
- Pareil sous Unix, je mesure l'étendue de mon ignorance en particulier sur les réseaux, et par extension un peu partout et surtout sur mon domaine de compétence : les maths. Je connais plutôt Linux (j'y bidouille), je suis un ignare sur Windows et pourtant on me qualifie de balaise en info. La bonne blague. Qu'on me donne à gérer le système du bahut et on va rire. ℓisllk★✉ 5 mai 2004 à 18:02 (CEST)
- Eh oui... Remarque, c'est bien l'image que je donnais de moi avant à mon entourage : toujours devant mon clavier, c'est moi qu'on appelle pour dépanner les PC (voire un Mac, une fois !) des uns et des autres, je passe, dans mon milieu socio-professionnel, pour un spécialiste (alors que je pense plutôt que ma connaissance de l'informatique me permet de mesurer mes lacunes). Depuis mon passage à Linux, c'est devenu pire : la preuve, l'administrateur réseau de mon collège (une soixantaine de postes) m'a fourni tous les droits pour le seconder (sous NT...). Et tous de me faire confiance. Bon, reconnaissons-le, je suis une sorte de geek. Vincent | 討論 5 mai 2004 à 17:43 (CEST)
- Ça-y-est, tu es un vrai geek ! ℓisllk★✉ 5 mai 2004 à 16:01 (CEST)
- Quant à moi, j'utilise setxkbmap pour charger au démarrage une table de /usr/X11R6/lib/X11/xkb/symbols/pc/ que j'ai modifiée à la main, comprenant l'espace insécable et plein d'autres trucs, ainsi que la possibilité d'appeler une autre table, celle du grec polytonique. Je lance le tout avec -layout fr,el-poly -option "grp:shift_toggle", qui appelle les tables fr et el-poly, cette dernière m'ayant été tricotée à la main par un ami qui l'a publiée sous license BSD. Vincent | 討論
- Ayé, j'ai trouvé : « keycode 65 = space nobreakspace » fait que shift+espace donne l'espace insécable. Il suffit de lire /usr/X11R6/include/X11/keysymdef.h sur ma Sarge, d'y lire le nom du caractère et d'enlever le préfixe XK_ en gardant la casse. En en plus, les codes unicode hexadécimaux sont placés en regard. ℓisllk★✉ 5 mai 2004 à 15:41 (CEST)
Alpha
Dans le même genre, le alpha est α, et je l'ai toujours tracé en forme de petit poisson, avec la patte supérieure qui dépassait. C'est grave, docteur ? ℓisllk★✉ 5 mai 2004 à 13:00 (CEST)
- J'imagine que tu n'es pas helléniste : je dis cela parce que j'ai souvent remarqué que les scientifiques traçaient les lettres grecques à la 6 4 2 (j'exagère un peu), surtout alpha α, théta θ et gamma γ. Pour théta, Unicode prévoit un caractère bis, ϑ U+03D1 (de même pour kappa, pi, etc.). Je dirais que ce n'est pas grave, mais bon, qu'on ne t'y reprenne plus. Vincent | 討論 5 mai 2004 à 14:37 (CEST)
- Aïe, pas la tête ! Je connais l'alphabet grec (astronomie aidant) mais effectivement je ne cause pas le grec, je le déchiffre mais je n'y comprends pas grand-chose : je comprends quelques mots grace à l'étymologie mais je ne saurais ni lire le grec moderne à haute voix ni le grec ancien. Il va bien falloir que je m'y mette un jour, comme au latin et à l'arabe. ℓisllk★✉ 5 mai 2004 à 14:54 (CEST)
- Oui, et plus vite que cela ! Vincent | 討論 5 mai 2004 à 15:38 (CEST)
- Aïe, pas la tête ! Je connais l'alphabet grec (astronomie aidant) mais effectivement je ne cause pas le grec, je le déchiffre mais je n'y comprends pas grand-chose : je comprends quelques mots grace à l'étymologie mais je ne saurais ni lire le grec moderne à haute voix ni le grec ancien. Il va bien falloir que je m'y mette un jour, comme au latin et à l'arabe. ℓisllk★✉ 5 mai 2004 à 14:54 (CEST)
Parthénon
Je suis passée voir l'article, c'est du beau boulot ! J'ai fait un peu de wikification et j'ai ajouté quelques détails (financement de la construction, comparaison avec les autres temples). Jastrow 6 mai 2004 à 12:49 (CEST)
- Merci. Je me suis servi de mes propres cours... Je viens de regarder la version anglophone : elle n'est pas mal et je pense qu'il y a encore matière à récupérer (dont les images ─ si leur copyright est clair). Je compte faire un plan du temple pour illustrer les notions architecturales. Vincent | 討論 6 mai 2004 à 18:22 (CEST)
Retranscription du grec
Salut Vincent,
Pour l'article Athènes, j'ai traduit/transcrit différents noms (maire, municipalités de la mégalopole). J'ai demandé vérification à une amie grecque, elle m'a répondu ceci, où elle m'explique le problème du nom au génitif au lieu du nominatif. Il faut donc choisir une convention : soit les noms sont mis au nominatif avant transcription, soit au génitif. L'avantage du nominatif, c'est que ça sonne plus familier (-polis au lieu de -poli) ; l'avantage du génitif, c'est que ça colle à l'usage grec ('fin d'après ce que j'ai compris, elle a pas été claire en ce qui concerne les municipalités qui ont l'air d'être au nominatif en grec et qu'elle a mis au génitif pour la transcription, mais là elle s'est absentée pour la semaine donc je peux pas lui demander). Qu'en penses-tu : nominatif ou génitif ? Merci de tes lumières ;-) Alibaba 9 mai 2004 à 16:57 (CEST)
- J'en pense que c'est assez difficile de répondre. À mon avis, il faut
- coller à l'usage français quand il existe (ce qui me semble en fait fort rare) ;
- proposer les deux graphies (quitte à mettre le s entre parenthèses, par exemple).
- Le nominatif est la forme du dictionnaire. Mais certaines Grecques sont connues en France sous leur nom au génitif, comme Nena Venetsanou (Νένα Βενετσάνου)... Je ne sais pas trop quoi te dire. Vincent ✐ 9 mai 2004 à 18:47 (CEST)
SOS Bailly
Salut Vincent, j'ai un trou terrible concernant la traduction de « ἑκάεργος » (c'est pour la page sur Apollon, rubrique « épithètes »). À l'étymologie, je dirais que ça veut dire « qui a le bras long », mais ça fait moyennement épique. Saurais-tu quelle est la traduction officielle ? Jastrow 12 mai 2004 à 20:13 (CEST)
- La traduction du Bailly est : « qui repousse au loin (avec ses flèches) ». J'ajoute que l'étymologie n'est pas claire mais qu'on peut y trouver ἕκας (ἑκάς en ionien-attique), « au loin ». Cf. ἑκηϐόλος, « qui lance au / de loin ». Vincent ✐ 12 mai 2004 à 20:28 (CEST)
- Merci. Ça explique pourquoi Leconte de Lisle traduit simplement par « l'Archer ». En revanche, Mazon traduit par « le Préservateur », pas glop... Jastrow 12 mai 2004 à 20:45 (CEST)
langues satem et langues centum
L'image sv:Bild:Indoeuropeiska_sprak_trad.jpg classe (divise) les [langues indo-européennes] en [langue satem] et [langue centum]. Il y a aussi des listes dans en:satem et en:centum
Est-ce exact ? Est-ce un classement à faire (aucune page sur les langues indo-européennes dans les autres langues ne le fait pour la liste des langues, sauf af:Indo-Europees, nl:Indo-Europese talen en commentaire de langue, sv:Indoeuropeiska språk dans l'image d'illustration), sachant qu'il est écrit « Non que cette opposition soit importante en soi » dans [langues indo-européennes].
N'hésitez pas à me répondre que vous ferez les articles [langue satem] et [langue centum] dans six ou douze mois, si c'est votre intention.
- C'est le cas ;-) En fait, la distinction entre les deux groupes est surtout importante au linguiste comparatiste et pour la compréhension de certains mécanismes phonétiques que ─ sans cela ─ on ne pourrait expliquer. Sorti de ce domaine, l'isoglosse qu'on peut tracer montre une répartition (presque) nette entre langues de l'Ouest et langues de l'Est, ce qui pourrait faire penser à un mouvement migratoire des Indo-Européens. Pourtant, cela ne coïncide pas avec les dates : les langues les plus anciennes ne sont en effet pas forcément du même côté de l'isoglosse : le sanskrit est satem, le grec centum. Vincent ✐ 14 mai 2004 à 19:12 (CEST)
Salut Vincent, sais-tu ù on pourrait mettre un lien à cet article? N'y a-t'il pas déjà qqch du même genre? -- Looxix
- Il y a déjà Diacritiques et Diacritiques de l'alphabet latin. Je prévoyais de faire, un jour, un tel article (en plus développé), et il en existe déjà un bout Accent circonflexe en français. Je m'en occupe (il suffit de déplacer et de supprimer les redites en liant correctement). Vincent ✐ 16 mai 2004 à 21:28 (CEST)
- C'est fait. Vincent ✐ 16 mai 2004 à 21:59 (CEST)
Noms grecs
Voici une petite liste de noms à vérifier
- Sisyphe Σισυφύς Sisyphus
- Protée Πρωτεύς Proteus
- Olympe Ὄλυμπος Olympos
- Odyssée Ὀδυσσεία Odysseía
- Tantale Ταντάλος Tantálos
- Pélops Πελοπς Pélops
- Déméter Δημήτηρ Dêmêter
- Styx Στυξ Styx
Dans ton dernier message, tu utilises Ἀνδρομέδα avec l'esprit sur l'alpha initial. Si j'ai bien compris, c'est parce qu'il s'agit d'un nom grec ancien et l'usage moderne écrirait Aνδρομέδα ? L'usage de Gorgonéion se limite-t-il seulement au bouclier, et sert-t-il à désigner aussi toute représentation de la tête de la Gorgone ? Tu peux répondre sur la section du même nom de ma page de discussion. Robin des Bois ♘ ➳ ✉ 18 mai 2004 à 20:54 (CEST)
- Je réponds ici, c'est plus simple. Pour l'esprit : tu l'as bien compris, seuls les mots en grec ancien utilisent l'esprit (voir Diacritiques de l'alphabet grec ─ je vends mes articles ;-). Mais il y a un autre problème : pour des raisons stupides, Unicode a codé différemment l'accent aigu ancien et l'accent simple actuel (alors que ce devrait être le même caractère). J'ai choisi de n'utiliser que l'accent aigu moderne car c'est celui que les polices de caractères ont le plus souvent (en fait, dès qu'elles ont ce qui faut pour afficher le grec polytonique ─ à plusieurs accents, esprits et iota souscrit : ήὴῆἠἡῃ, etc. ─ elles ont aussi l'accent monotonique).
- Ainsi, dans Ἀνδρομέδα j'utilise l'accent aigu moderne. Ἀνδρομέδα écrit ainsi est une sorte de monstre car je mélange des caractères polytoniques (Ἀ) et monotoniques (έ). Pour bien faire, il faudrait écrire Ἀνδρομέδα (tu devrais lire la même chose mais les deux ε accent aigu ne sont pas les mêmes caractères). Écrire Ἀνδρομέδα permet que plus de lecteurs puissent le lire et, surtout, est plus simple pour moi à gérer. Bon, je répondrai au reste plus tard. Vincent ✐ 18 mai 2004 à 23:35 (CEST)
Merci pour le petit mot Vincent. J'avais déjà fait les modifications et ajouts dans les pages concernées. J'ai copié/collé les termes pour êtres sûr de ne pas faire d'erreurs de caractères. Je me suis servi de ta méthode pour les insérer : (en grec motgrec aplhabetlatin) Robin des Bois ♘ ➳ ✉ 23 mai 2004 à 03:30 (CEST)
- Ok. Comme une modification en chasse une autre, je n'étais pas sûr que tu aies vu mon ajout dans ta page. J'ai aussi, dans la page de discussion de ta page d'utilisateur en chinois, apporté quelques informations Vincent ✐ 23 mai 2004 à 03:33 (CEST)
- Hmmm! As-tu été voir TOUTES mes pages perso dans les autres langues ? Si c'est le cas, merci de ton encadrement. Je suis humblement honoré ;-) Robin des Bois ♘ ➳ ✉ 23 mai 2004 à 06:31 (CEST)
- Oui. Non pas que je te pistes : je suis déjà casé ;-) Simplement, une fois où je suis passé par ta page d'utilisateur pour accéder à ta page de discussion, j'ai vu la foultitude de liens interwiki vers les autres pages. Or, il est rare qu'un contributeur qui n'est pas là depuis longtemps ait plusieurs pages d'utilsateur. En tout cas, pas tant. La curiosité aidant, je suis allé faire un tour... Vincent ✐ 23 mai 2004 à 09:17 (CEST)
- Ah, bon! Il semble donc que la curiosité est une autre qualité que nous ayons en commun. Je me suis créé tous ces comptes pour de simples raisons pratiques. De plus, si ça fait en sorte que plus de gens prennent contact entre wikis de langues différentes, je fais d'une pierre, deux coups. Dernier petit nom grec pour toi: Charon Χαρον. À bientôt! Robin des Bois ♘ ➳ ✉ 14 jun 2004 à 22:11 (CEST)
- Oui. Non pas que je te pistes : je suis déjà casé ;-) Simplement, une fois où je suis passé par ta page d'utilisateur pour accéder à ta page de discussion, j'ai vu la foultitude de liens interwiki vers les autres pages. Or, il est rare qu'un contributeur qui n'est pas là depuis longtemps ait plusieurs pages d'utilsateur. En tout cas, pas tant. La curiosité aidant, je suis allé faire un tour... Vincent ✐ 23 mai 2004 à 09:17 (CEST)
- Hmmm! As-tu été voir TOUTES mes pages perso dans les autres langues ? Si c'est le cas, merci de ton encadrement. Je suis humblement honoré ;-) Robin des Bois ♘ ➳ ✉ 23 mai 2004 à 06:31 (CEST)
Merci. Au fait, à propos de ta question sur la sybille de Cumes dans [Discuter:Charon (Mythologie)], j'avais bien raison. Il s'agit de l'Énéide VI, qui raconte le voyage d'Énée aux Enfers, accompagné de la prêtresse. Euh, en passant, pourrais-tu m'expliquer pourquoi certaines pages wikipédia, notamment en chinois, en coréen et récemment en français, m'apparaissent maintenant en caractères énormes, malgré le réglage de ma taille d'affichage ? Serais-ce un nouveau réglage du /monobook.css que je devrais effectuer? Robin des Bois ♘ ➳ ✉ 15 jun 2004 à 03:00 (CEST)
- Là, je ne vois pas. Il faudrait que tu m'indiques des pages où cela se produit. Vincent ✑ 15 jun 2004 à 07:08 (CEST)
- Sur toutes les pages en français, en japonais, en coréen et en chinois. Le problème a commencé quand j'ai fait une actualisation de ta page, comme si un bug s'installait dans la configuration par défaut de la page. Et les onglets en haut changent de position et s'alignent à la verticale quand on les survolent de la souris. IE ne me donne aucun message d'erreur. Que me conseilles-tu de faire (ou d'essayer) ? Robin des Bois ♘ ➳ ✉ 15 jun 2004 à 07:28 (CEST)
Salut,
Si tu pouvais voir si je ne dis pas trop de bétises...
Ce n'est qu'un début.
Merci d'avance Nataraja-Shiva 20 mai 2004 à 11:18 (CEST)
- J'ai surtout développé l'articles sur les emprunts aux langues amérindiennes. J'ai quelques questions sur les mots bardai et kamise : peux-tu m'indiquer quelles sont tes sources pour dire que le premier est bien relié à barde (ce que ne mentionne pas le Dictionnaire étymologique de la langue latine d'Ernout et Meillet) et que le second ne serait pas un emprunt d'une langue indienne au portugais, ce qui me semblerait plus logique. En effet, le même dictionnaire étymologique signale des formes proches dans les langues germaniques mais pas pour des langues indiennes.
- J'ai donc du mal à croire qu'il y a là des termes hérités de l'indo-européen mais j'y vois plus 1) une coïncidence comme il en eixste tant, 2) un emprunt croisé.
- D'autre part, cash en anglais ne vient pas d'une langue indienne mais de l'anglo-normand, forme d'ancien français, caisse, ce qui m'est confirmé par plusieurs dictionnaires de langue anglais ainsi que L'Étymologie anglaise de Paul Baquet (« Que sais-je ? » n° 1652). Pour les dicos en ligne, voir http://www.etymonline.com/c2etym.htm, http://www.bartleby.com/61/2/C0140200.html (American Heritage). En revanche, il existe un autre mot cash (cash2) venant du tamoul par portugais et désignant cette fois-ci une monnaie asiatique trouée au centre (et non le cash au sens français). Or, le mot cash français ne vient pas de ce cash2 mais de cash1. Le TLFi confirme, mais le Robert historique ni le Bloch et Wartburg ne citent ce mot.
- Pour les autres mots, je suis d'accord.
- Vincent ✐ 20 mai 2004 à 12:59 (CEST)
- Ok Pour chemise je l'avais gardé dans le doute, mais reclassé, du rédacteur précédent. Souvent entendu en Inde. Pour cash et bardai, je me basais sur le Dictionnaire de la civilisation indienne de Louis Frédéric. Peut-être une source peu sûre.
- Je ne dis pas que kamise ne s'utilise pas, mais je pense plus simple de considérer qu'il s'agit d'un emprunt à une langue européenne comme le portugais. Ah, le dictionnaire d'ourdou et d'hindi classique de Platts semble confirmer : « qamīṣ, vulg. qamīz, kamīj, s.m. A shirt; a shift; a chemise (cf. It. camicia; Port. camisa) ». C'est bien un emprunt.
- Pour bardai, j'ai beau chercher (et j'en ai, des dicos), je ne le trouve nulle part. Cela signifie sans doute qu'il est mal transcrit (vois pour kamise, qu'il faudrait écrire qamīṣ).
- Si tu veux un terme IE vraiment hérité et non emprunté, tu as l'embarras du choix. Par exemple hindi baṛbaṛ, (sanskrit barbara-) « gromellement » = grec βάρϐαρος bárbaros « personne qui bredouille » = « barbare » (cf. Redoublement).
- Louis Frédéric est quelqu'un dont j'apprécie beaucoup le travail. Mais comme souvent dans ce genre d'ouvrages, il n'a pas pu tout vérifier.
- Pour les mots que nous ont fournis les langues indiennes, tu peux consulter L'Aventure des mots français venus d'ailleurs d'Henriette Walter. Si tu ne l'as pas, je t'en donne quelques exemples. Sinon, une recherche étymologique avec le Petit Robert électronique (pareil : si tu n'as pas, je chercherai). Tu peux penser à punch (IE), coprah (non IE : tamoul), patchouli (tamoul), vétiver...
- Est-ce qu'il existe un équivalent de http://www.etymonline.com/ pour le français ?
- Nataraja-Shiva 20 mai 2004 à 18:12 (CEST)
- Pas à ma connaissance. Le TLFi possède cependant de bonnes rubriques étymologiques. Vincent ✐ 20 mai 2004 à 19:55 (CEST)
- Ok Pour chemise je l'avais gardé dans le doute, mais reclassé, du rédacteur précédent. Souvent entendu en Inde. Pour cash et bardai, je me basais sur le Dictionnaire de la civilisation indienne de Louis Frédéric. Peut-être une source peu sûre.
Justice
J'envisage, à contrecoeur, de reprendre en profondeur la page Justice qui me donne de l'herpès en l'état actuel. Dans l'hypothèse où les oeufs de Pâques n'auraient pas dégradé nos relations de manière irréversible, ce qui serait quand même dommage au regard du caractère sucré et moelleux du sujet, pourrais-tu me fournir quelques mots ou lignes sur l'étymologie du mot, ici ou directement en tête d'article ? Merci de ce que tu pourras faire. villy 21 mai 2004 à 08:28 (CEST)
- Beuh, pourquoi nos relations auraient-elles été entachées ? Nous avons discuté de manière courtoise et sensée. Pour justice (bon courage, c'est le type même d'articles qui me donne la nausée, mutatis mutandis), je peux te fournir une étymo, que je placerai directement dans l'article. Vincent ✐ 21 mai 2004 à 19:06 (CEST)
- Merci beaucoup, vraiment, ça me fournira l'impulsion de départ dont j'ai besoin. villy 21 mai 2004 à 23:47 (CEST)
J'ai rétabli les choses telles qu'elles étaient lorsque la situation ne semblait pas en mesure d'occasionner tant de dégâts physiologiques, j'espère que la petite modification sur la page utilisateur de villy a été prise pour pour ce qu'elle est (une boutade) : je pensais au caractère imbuvable de l'article justice depuis un moment et avais même pensé en parler à notre brillant magistrat mais m'étais abstenu étant données les réserves qu'il a pu émettre quant à sa participation aux articles traitant de son environnement professionnel ; puisqu'existe Modèle:Série Justice, Modèle:Droit pourrait être proposé à la suppression voire que la demande en soit faite de façon directe à un administrateur puisque je (son auteur) ne m'oppose à ladite suppression : à villy de voir quel(s) nom(s) et quel(s) contenu(s) de MediaWiki(s) sur le thème est/sont le plus pertinent(s) ; je profite de ce message pour transmettre à Vincent combien j'ai apprécié sa prose aux liens étranges sur Haaahaaahaaa de Pontauxchats et ses prouesses sur Gimp (remarquées avant le mot sur le bistrot mais devant le concert d'éloges une couche de plus m'était alors apparue comme inutile, cependant les compliments sont en général bons à prendre tant que restent surveillées les circonférences du crâne et des chevilles, alors voilà ;-) et à villy que je lui souhaite aussi bon courage pour l'article auquel il s'attaque en espérant lui avoir rendu la pente moins raide. ; Amaury 22 mai 2004 à 04:24 (CEST)
Merci Vincent pour ton message (je l'ai transmis à villy). ; Amaury 26 mai 2004 à 17:24 (CEST)
Comprends-tu l'islandais?
Salut Vincent, si tu comprends ou décryptes quelque peu l'islandais pourrais-tu me dire plus ou moins ce qui se trouve sur cette page is:Wikipedia:Stjórnendur (je crois que c'est une demande pour être sysop; mais je n'en suis pas sûr). Merci d'avance. -- Looxix
- Très balaise car les racines germaniques ne sont pas mon fort et cette langue n'utilise pour ainsi dire aucun mot savant tiré du latin ou du grec. En gros, cela parle d'« administrateurs sur Wikipédia » (Stjórnendur á Wikipedia), « qui sont ceux qui ont » (eru þeir sem hafa) « les droits aussi dits de sysops » (svokölluð 'sysop' réttindi). Le reste est beaucoup plus flou. Il est question, en vrac, de « ce que le programme de Wikipédia (ou la direction de Wikipédia) » « attribuer (je continue mot à mot) tel droit quelqu'un... volontairement jusqu'à... tout ceux qui ont falloir devenir administrateur de Wikipédia »... J'arrête là, c'est trop dur car la phrase est trop longue (et en plus, j'ai laissé tomber tous les cas et j'ignore la syntaxe).
- La suite dit (traduction intuitive et sûrement très fautive) « les administrateur n'ont aucun autre pouvoir particulier excessif (?) sur Wikipédia en ce qui concerne la rédaction d'articles (?) et ont accès aux quelques zones qui sont réservées / fermées ... général par sécurité ».
- Enfin :
- « les admins peuvent :
- (peut-être) bloquer/débloquer des pages (?) ;
- modifier des pages bloquées ;
- effacer des pages ;
- Etc., le reste se comprend facilement (bloquer des IP, etc.). J'espère malgré tout t'avoir été quelque peu utile. Pour le coup, je ne brille pas trop... Vincent ✐ 22 mai 2004 à 00:17 (CEST)
- Magnifique! Il s'agit donc bien de l'équivalent de la page Wikipédia:Administrateur. Merci beaucoup. A+ -- Looxix
Danemark ou Danemark ?
Salut Vincent, j'ai encore un service à te demander: est-ce qu'on dit "royaume du Danemark" ou "royaume de Danemark"? Pareil pour "Harald II du Danemark" ou "Harald II de Danemark"? Y-a-t'il une règles à ce sujet ou c'est l'usage qui décide? Merci d'avance. -- Looxix 24 mai 2004 à 23:26 (CEST)
- Honnêtement, je ne sais pas. De plus, Google donne des chiffres proches pour les deux emplois. Quant à savoir si une règle existe ou bien si c'est l'usage... Mes différentes sources n'en parlent pas. Si la question est importante, j'irai la poser surdansà news:fr.lettres.langue.francaise : j'y suis bien reçu. Vincent ✐ 24 mai 2004 à 23:48 (CEST)
- [2] Une réponse sur le pourquoi du probléme, j'ai cherché dans une base de données et les auteurs du 19iéme utilise "de Danemark" ou "en Danemark" phe 25 mai 2004 à 00:02 (CEST)
langues ouraliennes
Et personne ne pouvait me dire que je m'était trompé dans les articles des langues ouraliennes ?! (28 mai 2004)
- Désolé, je ne m'en étais pas aperçu. Vincent ✐ 28 mai 2004 à 17:31 (CEST)
J'ai finis par m'en rendre compte, en faisant une vérification générale des articles des langue aujourd'hui. (28 mai 2004)
Note pour plus tard : penser à synchroniser [langues indo-européennes] avec [langues par famille] (je pense avoir synchronisé dans le sens inverse) (28 mai 2004)
langues slaves
Allez vous mettre en application les principes énnoncés dans [Discuter:Langue_romane] sur les articles des [langues slaves], en particulier Utilisateur:213.191.148.136 et Utilisateur:213.191.130.179 ?
- Voyez les modifications de cette personne, telles : le serbo-croate comme invention communiste (et les conséquences dans tous les articles des langues, surtouts ceux des langues slaves), le bosnien (sic), le bélarus (sic)...
- Ah... Je ne connais pas assez le sujet pour argumenter. Du moins, ce que je connais pourrait être dépassé. Je préfère me taire. Vincent ✐ 30 mai 2004 à 23:45 (CEST)
- J'ai une question plus générale pour Vincent: comment fait-on pour savoir si l'on est en présence d'une langue ou d'un dialecte? Jyp 30 mai 2004 à 23:52 (CEST)
- On ne fait pas : il n'y a pas de différence objective. Qualifier telle langue de dialecte / patois ou de langue ressortit à la politique, la culture ou l'histoire mais pas à la linguistique. En effet, aucun critère formel n'existe. Pour moi, les seules différences objectives sont :
- langue ;
- pidgin ;
- créole (ancien pidgin devenu langue).
- Sorti de cela, il n'y a rien de précis. Si la question t'intéresse, je peux chercher dans The Power of Babel de MacWhorter, qui consacre, pour démonter ce mythe, une grande partie de son ouvrage. Les exemples abondent. Vincent ✐ 31 mai 2004 à 00:19 (CEST)
- Cela confirme ce que j'avais compris: c'est un acte politique de ces pays qui utilisent la langue comme moyen de promouvoir leur identité nationale. Jyp 31 mai 2004 à 19:31 (CEST)
- Exact. Voir par exemple ce qu'on appelle en France des patois, le serbe et le croate qui sont considérées comme des langues alors qu'elles sont plus que très proches et intercompréhensibles, et les dialectes chinois, nommés ainsi alors qu'il n'y a d'intercompréhension qu'à l'écrit. Tout cela n'est que culturel et surtout politique. Vincent ✐ 31 mai 2004 à 23:04 (CEST)
- Cela confirme ce que j'avais compris: c'est un acte politique de ces pays qui utilisent la langue comme moyen de promouvoir leur identité nationale. Jyp 31 mai 2004 à 19:31 (CEST)
- On ne fait pas : il n'y a pas de différence objective. Qualifier telle langue de dialecte / patois ou de langue ressortit à la politique, la culture ou l'histoire mais pas à la linguistique. En effet, aucun critère formel n'existe. Pour moi, les seules différences objectives sont :
Recherches avec Google
Bonjour,
Il se passe une chose étrange avec Google, au moment où j'écris, du moins. Toutes les recherches que j'y lance concernant un article de Wikipédia (sans spécifier le site sur lequel limiter la recherche) semblent exclure Wikipédia. Il est simple de le constater avec des articles que j'ai écrits qui ne se trouvent nulle part ailleurs sur la web (Apophonie accentuelle en russe, Phonème éphelcystique) ou d'autres qui, il y a peu, étaient toujours classés en premier : ils sont maintenant absents d'une recherche et seuls les miroirs apparaissent. Étrange, non ?
Par exemple... Vincent ✐ 4 jun 2004 à 12:41 (CEST)
Salut, j'ai essayé avec le lien que tu as donné et chez moi le premier lien est un lien vers la wikipedia (fr.wikipedia.org). Peut-être qu'un robot était en train de parcourir le site quand tu as essayé et que quand ils parcourent, ils éffacent d'abord tous les liens (je ne sais pas comment fonctionne google en interne)
- Cela marche ici aussi. Mais il y a plusieurs serveurs google, répartis dans différents pays, et il ne sont pas toujours synchronisés. Il faudra surveiller si c'était un phénomène isolé et temporaire où si le problème se répend. Jyp 4 jun 2004 à 14:00 (CEST)
- Maintenant, tout est bon. En fait, j'ai l'impression que Google a été hacké pendant quelques dizaines de minutes. En effet, quelle que fût la recherche, un lien vers un site de téléchargement de MP3 était cité en premier puis, sous ce site, quelques autres sans trop de rapport, mais toujours les mêmes. Étrange.
- Ca ressemble plus à un DNS poisonning. Jyp 5 jun 2004 à 11:29 (CEST)
- Maintenant, tout est bon. En fait, j'ai l'impression que Google a été hacké pendant quelques dizaines de minutes. En effet, quelle que fût la recherche, un lien vers un site de téléchargement de MP3 était cité en premier puis, sous ce site, quelques autres sans trop de rapport, mais toujours les mêmes. Étrange.
Heuh, Екатери́на je suppose que ça veut dire Catherine ;o) mais vu mes connaissances en Russe, j'ai pas osé rectifier... heMmeR 4 jun 2004 à 13:46 (CEST)
Numération vicésimale et soixante-dix
Salut Vincent. On se posait une question avec quelques wikipédiens. Quelle est l'orgine de « soixante-dix » (on ne dit pas « quarante-dix » pour « cinquante »...)? Autant « quatre-vingt » et « quatre-vingt-dix » seraient expliqués par un ancien système de numération vicésimale utilisé par les Gaulois, autant pour « soixante-dix » on ne voit pas d'explication. On se dit que cela devrait être « trois-vingt-dix ». Mais force est de constater que ce n'est pas le cas. Aurais-tu quelques lumières à nous apporter concernant cette délicate question? Merci d'avance Med 5 jun 2004 à 15:32 (CEST)
- Oui. Cette question n'est pas résolue mais cela fait un petit moment que l'on exclut une origine gauloise (voir à Gaulois) ou, du moins, que celle-ci est fortement critiquée. C'est une question dont nous avons très souvent débattu dans news:fr.lettres.langue.francaise. Vous pouvez consulter les archives par Google. Par exemple : cet article ou celui-là. Vincent ✐ 5 jun 2004 à 15:42 (CEST)
- Merci Vincent. Je pense qu'on pouvait encore se poser la question longtemps. Si même les spécialistes n'ont pas de réponse définitive, alors ... Med 5 jun 2004 à 16:01 (CEST)
- Une petite remarque: les textes en français "ancien" (ex. Molière) utilisent septante, huitante et nonante, qui sont (partiellement) restés en usage en Suisse et en Belgique (Il y a aussi un bâtiment parisien qui s'appelle «l'hôtel (ou l'hôpital) des six-vingts»). Cela tend néanmoins à corroborer une invention récente (postérieure à Molière), ou alors leur origine allogène à la langue parlée à l'époque. Jyp 5 jun 2004 à 15:51 (CEST)
- Il y a même aussi l'« hôpital des quinze-vingt », en référence aux trois cent malades qu'il pouvait accueillir lors de sa fondation. Med 5 jun 2004 à 16:01 (CEST)
Voyelles latines en API
Salut Vincent. Alors que je m'attèle à l'amélioration de Ancien français, j'hésite sur la transcription des voyelles latines en API. Moi j'ai étudié la linguistique historique avec l'alphabet des romanistes : 5 voyelles latines x 2 longueurs = ā ă ē ĕ... Mais comme je voudrais écrire l'article en API, je me demande si on utilise un autre système pour la phonétique latine dans ce cas. Tu peux peut-être m'éclairer ? --Serge(iNyar)
- En fait, je trouverais plus simple de garder pour le latin le système de Bourciez / alphabet romaniste car c'est celui que tout étudiant en lettres a étudié (au contraire de l'API). Mais bon.
- Tout d'abord, je pense qu'il n'est pas possible de fournir une notation phonétique mais seulement phonologique, donc entre barres obliques. En effet, nous ne savons rien de la réalisation physique et articulatoire exacte des sons latins (les auteurs antiques ayant traité de phonétique ne sont en effet jamais aussi rigoureux que ce que demande une transcription phonétique) et la seule chose qui importe est leur traitement en tant que phonèmes. Donc : transcription phonologique, j'insiste. On laissera de côté certains détails, ou bien ce sera de la pure hypothèse, ce qui n'est pas vraiment compatible avec la phonétique (qui juge ce qu'on entend ou réalise). Nous ne connaissons de la phonologie latine que des systèmes d'opposition (on sait que tel ou tel son est plus ouvert que tel ou tel autre, mais rien qui permette de dire que c'est un [ɜ] ou un [ɞ] ou un [ɛ], etc).
- Dans ce cas, il n'y a pas besoin d'être très précis. On obient alors /a(ː)/, /e(ː)/, /i(ː)/, /o(ː)/, /u(ː)/ et /y(ː)/ (ce dernier pour les mots empruntés au grec, prononcé /u/ ou /i/ dans la langue populaire). Ici, les symboles /e/ et /o/ notent bien des voyelles fermées mais on ne sait pas de quelle aperture précise. On peut cependant penser, d'après l'évolution des voyelles dans les langues romanes, qu'une voyelle longue était plus fermée que sa contrepartie brève (/a/ restant cependant peu concerné). Dans ce cas : /a(ː)/, /ɛ/, /eː/, /ɪ/ (?) /iː/, /ɔ/, /oː/, /ʊ/ (?), /uː/. C'est cependant de la pure hypothèse.
- Pour les diphtongues classiques (en laissant de côté les diphtongues archaïques) : /ae̯/, /oe̯/, /au̯/.
- On sait d'autre part que :
- æ était réalisé plus ou moins /ɛː/ à partir du IIe s. avant notre ère mais /eː/ dans les campagnes (d'où quelques mots français issus de termes en æ qui ont subi le même traitement que s'il étaient issus de mots en ē : sæta → soie, alors que æ a normalement été confondu avec ĕ /ɛ/. Il faut noter le cas de Cæsar, que Claude a fait écrire Caisar et prononcer /kai̯sar/, prononciation pseudo-archaïsante qui n'est restée qu'en Germanie sous la forme kaisar, en gotique, puis Kaiser, etc. Le latin a conservé la graphie æ parce qu'il ne possédait de signe pour le phonème /ɛː/ ;
- œ est devenu /eː/ au IIe s. avant notre ère ;
- au est resté /au̯/ sauf dans le parler rural et quelques quelques mots ruraux où il est confondu avec ō (cauda → cōda ; pour les langues romanes, il faut partir de ce cōda et non de cauda pour expliquer les mots obtenus de cet étymon). Les langues romanes ne l'ont, du reste, pas toutes fait monophtonguer et si c'est le cas, c'est un développement qui leur est propre et non latin. Noter que au suivi, dans la syllabe d'après, d'un o ou d'un u passe à /a/ dès l'époque impériale, d'où August-{us|a} → Agust- → août, agosto, Aoste, etc.
- Il y aurait encore un grand nombre de détails notables, qui concernent cependant des points qui ne sont pas utiles pour la phonétique historique du français. J'espère avoir répondu à ta question. Vincent ✑ 16 jun 2004 à 20:04 (CEST)
- Sources : Phonétique historique du latin de Max Niedermann, La phonétique historique du latin dans le cadre des langues IE d'Albert Manet, Précis de phonétique historique de Noëlle Laborderie.
- P.-S. Quelques notions supplémentaires de phonétique latine dans Scansion, que j'ai écrit il y a peu.
- Ce petit texte ferait un bon début pour un article Prononciation du latin, non? Jyp 16 jun 2004 à 21:01 (CEST)
- Garder le système de Bourciez, je n'ai rien contre, c'est juste que je me demandais si, à part les étudiants en lettres, il était utilisé ailleurs (je ne l'ai jamais vu que dans mes cours de phonétique historique). Mais ça m'arrangerais de le garder effectivement, parce que j'ai encore du mal avec l'API.
- D'accord pour "phonologie", je confond(ai)s encore un peu phonétique et phonologie. Merci de m'avoir repris.
- Il suffit de ce souvenir que la phonétique est un cliché, un instantané de ce qu'on entend (ou de ce qu'on devrait entendre), indépendamment de la langue. C'est une description physique. La phonologie ne s'intéresse pas à la réalité des sons mais au système propre à une langue.
- En tout cas, merci beaucoup pour tes explications (et pour tes corrections sur mon début de texte - j'avais interrompu pour aller manger, d'où les crasses qui restaient).
- De rien. Je suis au contraire très heureux que quelqu'un d'autre s'intéresse aussi à la phonlogie.
- Il y a encore deux subtilités qui m'échappent. Parfois tu utilises « /eː/ » et d'autres fois « ē », alors est-ce que j'ai bien compris si je dis que le premier est en API, le second dans le système de Bourciez ?
- Exact. Mais le symbole [ē] existe en API : c'est un [e] prononcé sur un ton à registre moyen.
- Et s'ils sont tous les deux utilisés en API, quelle est la différence ? Et autre chose : pourquoi parfois isoler le phonème entre barres obliques et d'autre fois l'écrire en italique ? sur quoi fais-tu la différence ? Merci d'avance. --Serge(iNyar) 16 jun 2004 à 21:59 (CEST)
- Je suis un usage qui ne m'est pas propre mais que je trouve pratique : en italique tout autonyme (lettre citée en tant que lettre, symbole en tant que symbole, mot en tant que mot) et mot étranger (sauf si l'alphabet est différent). Or, le système de Bourciez n'est pas une transcription phonétique API : comme toute autre transcription, je la mets en italique. Le problème principal, c'est que les transcription phonologiques, entre barres obliques, n'utilisent pas un API strict. Par exemple, il est courant de se servir du macron pour les voyelles longues. On trouvera donc souvent /ē/ pour désigner /eː/. Vincent ✑ 17 jun 2004 à 00:26 (CEST)
Comité de pilotage
Salut Vincent. Ce petit mot pour te rappeler l'existence de l'important vote en cours pour le comité de pilotage de l'association. On a besoin de l'avis de tous ! Je t'invite à voter à : Wikipédia:Wikimédia francophone (Élection du comité de pilotage). Wiki-citoyen ! villy 26 jun 2004 à 14:09 (CEST)
Liste de tes images
Bonjour,
Un admin pourrait-il lancer une requête SQL pour recenser toutes les images que j'ai téléchargées sur le serveur, afin que je rende leur licence plus explicite ? Merci, Vincent ✑ 28 jun 2004 à 03:20 (CEST)
- À 07h30 heure française, impossible d'accèder à la base pour les requêtes SQL ... Je pensais que l'accès aux requêtes SQL était de retour, pas sur que ce soit le cas. Si quelqu'un a plus d'infos. Tipiac 28 jun 2004 à 07:28 (CEST)
- Pour l'instant, les administrateurs n'ont toujours pas accès aux requêtes SQL mais ça pourrait revenir. En attendant, trois solutions :
- demander a développeur de lancer la requête ;
- demander a quelqu'un qui a une version de Wikipédia récente chez lui de lancer la requête ;
- récupérer la liste complète des images et y chercher ton nom.
- A☮ineko ✍ 28 jun 2004 à 08:59 (CEST)
- Pour le n°3, c'cest surement plus rapide de consulter ses contributions en 500 par 500 --Pontauxchats Ier | ✉ 28 jun 2004 à 10:46 (CEST)
- Je pourrai essayer de faire le 2, mais pas avant ce soir au plus t^ot. Med 28 jun 2004 à 11:46 (CEST)
- Merci. Je vais attendre. Vincent ✑ 28 jun 2004 à 13:47 (CEST)
- Mission accomplie. Le résultat est sur ta page de discussion. Med 28 jun 2004 à 23:48 (CEST)
- Pour l'instant, les administrateurs n'ont toujours pas accès aux requêtes SQL mais ça pourrait revenir. En attendant, trois solutions :
Salut Vincent. J'ai fait une requête SQL sur le dernier dump pour avoir la liste de tes images. Si tu as d'autres demandes, n'hésite surtout pas. Med 28 jun 2004 à 23:46 (CEST)
select cur_title from cur where cur_namespace=6 and cur_user_text="Vincent Ramos" order by cur_title;
Accueil_trop_espace.png Allah_ligature.png Apex_latin.png Aqueduc_Peyrou.jpg Arabe_arch.png Aram_nabat_arabe_syriaque.png Bangla.png Barcelone_Parc_Guell_(1).JPG Barcelone_Parc_Guell_(10).jpg Barcelone_Parc_Guell_(11).jpg Barcelone_Parc_Guell_(2).JPG Barcelone_Parc_Guell_(3).JPG Barcelone_Parc_Guell_(4).JPG Barcelone_Parc_Guell_(5).JPG Barcelone_Parc_Guell_(6).JPG Barcelone_Parc_Guell_(7).JPG Barcelone_Parc_Guell_(8).JPG Barcelone_Parc_Guell_(9).JPG Boustrophedon.png Bémol.png Cap_min.png Capture_accueil_opera_linux_Vincent_Ramos.png Carte_Localisation_Région_France_Auvergne.png Chuan_arch.png Chuan_sigil.png Circonflexes_de_Sylvius.png Circulus_super_capite.png Comedie.JPG Comp_arabe_hebreu_etc.png Comp_arabe_hebreu_etc2.png Compa.jpg Coulees_du_Vesuve.jpg Coupe_oeil.jpg Cour-Heidelberg.jpg Cyrillique_cursif.png Cyrillique_serbe_russe.PNG D_r_nabat_syriaque.png Dasus.png Deflechi_lao.png Deflechi_wang.png Dièse.png Do_maj.mid Drole_de_truc_qui_se_passe.png Dvorak.jpg Emprunt_lai.png Emprunt_wan.png Exemple_gotique.png Exemples_bicamerales.png Extrait_du_dico_de_styles_caligraphiques.png Gotique.png Graffiti_politique_de_Pompei.jpg Gui_arch.png Gui_sigil.png Gujarati.png Hanzi_image.png Hebreu_hist_arabe.png Hindi.png I_longa.png Immeuble.jpg Imprime_shuo.png Innocent.jpg Innocent_petit.jpg Inscription_sideen.jpg Italique_cursive.png Italique_oblique.png Kryptonite.png Kryptonite2.png Ligature_arabe_lam_alif.png Ligature_grecque_kai.png Ligatures_arabes_optionnelles.png Ligatures_latines_courantes.png Lithuania_coa.png Logo_ecriture_Japon.png Logo_sinogrammes.png Long_arch.png Long_sigil.png Léguman.jpg Ma_arch.png Ma_sigil.png Manuscrit_shuo.png Manuscrit_shuo2.png Megatokyo-strip381_s.png Mu_arch.png Mu_sigil.png Nepali.png Niao_arch.png Niao_sigil.png Nuu_arch.png Nuu_sigil.png Om_manipadme_hum_sanskrit.png Panjabi.png Pavillon_Peyrou.jpg Pavillon_Peyrou2.jpg Peyrou.jpg Phon_gotique.png Phon_gotique2.png Phon_gotique3.png Phrase_sanskrite.png Psilon.png Punctum superscriptum.svg Radical_de_sinogramme_ma1.png Radical_nuu_hao.png Radical_nuu_jie.png Radical_nuu_ma.png Radical_nuu_qie.png Radical_nuu_ta.png Radical_nuu_xing.png Radicaux_de_luan.png Religion_grecque.png Ren_arch.png Ren_sigil.png Ri_arch.png Ri_sigil.png Ridicule.jpg Rouge2.jpg Rue.JPG Sanskrit.png Sanskrit_rate.png Shan_arch.png Shan_sigil.png Shui_arch.png Shui_sigil.png Sinogrammes_style_courant.png Sinogrammes_style_regulier.png Sinogrammes_style_scribes.png Sinogrammes_style_sigillaire.png Soutra_du_diamant.png Soutra_du_diamant_ouvert.png Svastika.png Tableau_de_radicaux_en_composition.png Tableau_des_diacritiques_latins.png Tamil.png Telugu.png Test_Unicode_API.png Test_Unicode_ChinoisSimpl.png Test_Unicode_ChinoisTrad.png Test_Unicode_Grec.png Test_Unicode_Grec2.png Test_Unicode_latin.png Test_arabe2.png Test_arabe3.png Test_arabe4.png Test_arabe6.png Test_arabe7.png Test_arabe8.png Texte_sino_japonais.png Urdu.png Variantes_contextuelles_en_arabe.png Variantes_contextuelles_en_arabe2.png Variantes_contextuelles_hebraiques.png Variantes_contextuelles_latines.png Variantes_contextuelles_latines2.png Variantes_contextuelles_latines3.png Vincent_Ramos.jpg Voir_aussi.png Voyelles_monotoniques.png Vue_Carre_St-Anne.jpg Vue_du_Vesuve.jpg Wikiarabe.png Yu_arch.png Yu_sigil.png Yue_arch.png Yue_sigil.png Zhu_arch.png Zhu_sigil.png Zi_arch.png Zi_sigil.png
Je vois que tu as déjà eu ta reponse :o) La prochaine fois, tu peux utiliser la page http://meta.wikipedia.org/wiki/Requests_for_queries. Tiens, j'ai passé une p'tite macro sur la liste ci-dessus pour y ajouter des liens et une vignette. Si ca peux servir... A☮ineko ✍ 29 jun 2004 à 05:33 (CEST)
Voir Utilisateur:Vincent Ramos/Images
Bon bein je suis tombé sur certaines de tes images et y ai mis licenceInconnue, mais maintenant que tu as la liste, ça devrait changer donc je te les liste pas la. Bonne chance pour les licences et merci ! Tipiac 29 jun 2004 à 12:25 (CEST)
Tokyo, Tōkyō ou Tôkyô?
Salut Vincent. Avec Aoineko nous sommes en train de réfléchir sur les conventions de nommages concernant les articles dont le titre a une origine étrangère, comme « Ðiện Biên Phủ » par exemple. Nous sommes à peu près tombés d'accord qu'il ne faudrait accepter dans les titres que les caractères des quatre premières zones de l'unicode (je ne sais pas si le terme est correct) : Latin de base; Supplément Latin-1; Latin étendu A; Latin étandu B. Cependant, un léger soucis se pose concernant les noms provenant de langues qui ne s'écrivent pas naturellement avec un alphabet latin. Un exemple précis est « Tokyo ». Aoineko pense qu'il vaut mieux écrire « Tokyo » car c'est l'orthographe la plus répandue. Personnellement je penche plutôt vers « Tōkyō » afin de conserver une certaine richesse. Il reste aussi « Tôkyô » comme possibilité. Qu'en pense le linguiste? À titre personnel je préfère qu'on utilise une orthographe rare mais correcte que répandue et incorrecte :). Merci d'avance pour tes lumières. Med 29 jun 2004 à 15:03 (CEST)
- Pour ma part, je penche pour l'orthographe le plus français (si, c'est correct) possible : Tokyo, Pékin, Canton, etc., dans le titre. Ailleurs, une fois que l'équivalent a été donné, la transcription scientifique adoptée (kunrei, pinyin...). Il ne faut à mon avis pas coder les titres en Unicode brut : serons-nous, sinon, correctement référencés par les moteurs de recherches (qui, à mon avis, donnent moins d'importance à une page de redirection, vers laquelle peu de liens pointent, qu'à l'article lui-même), les internautes trouveront-ils facilement la page ? Je ne sais pas trop. Vincent ✑ 29 jun 2004 à 19:27 (CEST)
- Je suis content d'entendre ça de la part de quelqu'un que j'estime être un puriste. -- Looxix 30 jun 2004 à 00:40 (CEST)
- Tout dépend de la façon dont la redirection est faite. Si une nouvelle page est constuite, comme c'est le cas je pense, alors une redirection nous apporte même un meilleur référencement. Les utilisateurs n'auront strictement aucun problème pour trouver les articles contenant des caractères non latin-1 dedans, les redirections sont faites pour ça d'ailleurs. Sinon, le Petit Robert utilise souvent l'orthographe étrangère, pour « Ðiện Biên Phủ » par exemple. Tu considères qu'ils se trompent? À titre personnel je pense que ce serait une perte de ne pas utiliser des caractères non latin-1. Quand je vois la façon dont les gens massacrent la prononciation étrangère, si en plus on les habitue à croire que ça ne s'écrit qu'avec des lettre françaises ça ne risque par d'améliorer la situation. Med 30 jun 2004 à 02:54 (CEST)
- Je sais que ç'n'est pas trop rélévant, la policie sur le Wikipédia anglais est à utiliser le nom anglais et à donner le nom local qu'une fois dans l'article. Dans l'article en:Tokyo, on voit:
- Tōkyō (東京; lit. eastern capital) is the capital of Japan as well as the most populous conurbation in Japan, and the most populous metropolitan area in the world.
- A little more than 12 million people live in Tokyo...
- Je conseillerais qu'on fasse le même chose ici. On utilise Tōkyō qu'une fois à la tête de l'article et d'ailleurs (entr'eux le nom de l'article) on écrit Tokyo, sans diacritiques. — OwenBlacker | Discussion 30 jun 2004 à 04:01 (CEST)
- Je sais que ç'n'est pas trop rélévant, la policie sur le Wikipédia anglais est à utiliser le nom anglais et à donner le nom local qu'une fois dans l'article. Dans l'article en:Tokyo, on voit:
- Je réponds en vrac :
- Looxix → je suis surtout puriste de la langue française ;-)
- Med → je suis d'accord, mais il me semble qu'il faille nommer la page en français et proposer des redirections dans l'orthographe locale / la transcription scientifique. Pour le Petit Robert (même chose avec le Quillet), il faut noter qu'ils pratiquent aussi la redirection (dans mon Quillet, par exemple « Canton, voir Guǎngdōng », etc.). Leur problème est cependant différent du nôtre : un lecteur ne sachant pas comment s'écrit en quôc ngu Ðiện Biên Phủ possède un outil très tolérant à l'erreur : la recherche empirique en feuilletant le dictionnaire. Ðiện Biên Phủ sera classé comme s'il était écrit Dien Bien Phu, ce qui n'est pas possible avec un outil de recherche informatique : nous n'avons pas de vrai index alphabétique, ou bien il est fastidieux à consulter, et les lettres ne seraient pas classées dans le même ordre. Bref, celui qui cherche dans le dico n'a pas besoin de connaître l'orthographe diacritée : le mot est facilement accessible.
- OwenBlacker → tout à fait d'accord, d'autant plus que si l'on pratiquait absolument la variante scientifique, rien n'interdirait d'écrire dans tout l'article Περικλῆς au lieu de son nom en alphabet latin, par exemple. Vincent ✑ 30 jun 2004 à 07:01 (CEST)
- Je réponds en vrac :
A quand un titre du genre :
| |
C'est une blague bien entendu (quoique...) A☮ineko ✍ 30 jun 2004 à 07:55 (CEST)
Articles vietnamiens déplacés
Salut Vincent. Pourquoi es-tu en train de déplacer tous les articles vietnamiens? Je ne vois aucune justification à tous ces déplacements. Pour moi revenir à des caractères français ne fera qu'augmenter le travail des contributeurs dans le futur et c'est reprendre les même limites que les encyclopédies papier. De ce que j'ai vu, la quasi totalité des arguments en faveur d'une orthographe française sont totalement fallacieux. Enfin, j'ai dû me battre des mois pour faire accepter l'utf8 (là aussi on m'a opposé nombre d'arguments totalement fallacieux). Encore une nouvelle bagarre qui commence :-( Med 1 jul 2004 à 02:06 (CEST)
- Non non. Je pensais qu'un consensus était atteint quant à la nécessité de présenter des articles dont le titre fût en latin-1, de façon à être, par exemple, plus faciles d'accès en cas de recherche (peu de personnes vont taper dans Google Histoire du Việt Nam mais plutôt Histoire du Viet Nam ou ... du Vietnam. Or, Google classe les liens, entre autres, selon le nombre de pointeurs. Je ne conteste nullement, au contraire, je m'en sers pour presque tous « mes » articles, l'utilisation d'Unicode. Si tu me donnes tort, n'hésite surtout pas à annuler mes déplacements (si tu en as la possibilité). Je ne souhaite absolument aucun conflit. Pour moi, un conflit d'opinions ne devrait pas s'étendre. Vincent ✑ 1 jul 2004 à 02:32 (CEST)
- Comme l'a dit phe sur l'histoire du bistro, il faudrait regarder de plus près le problème des redirects pour voir leur référencement. Sinon le but final n'est pas de faire un article qui soit le mieux référencé sur google mais qui soit le plus exact possible (même si au stade actuel google nous aide bien). :o) Pour les recherches des utilisateurs, je pense qu'il faut faire le plus de redirects possibles afin de faciliter la recherche. Med 1 jul 2004 à 10:59 (CEST)
Pourriez vous remplacer, dans l'article Mepis, « un second étant » par « un deuxième étant » ? J'aimerai savoir si [Utilisateur:Hada de la Luna] peut se dégouter toute seule de (la rédaction d'articles dans) fr.wikipedia.org. (Mon avis sur les noms|titres d'articles est clair).
- "second" vs. "deuxième" : le Bon usage de Grevisse et Goosse rapporte (§ 581 b) 2°) :
« Les rapports de second avec deuxième ont fait l'objet de prescriptions arbiraires : tant que second a été la forme la plus courante, les grammairiens réservaient l'emploiu de deuxième au cas où la série comprenait plus de deux termes ; quand second est devenu plus rare, ils ont voulu réduire celui-ci au cas où la série ne compte que deux termes. L'usage a toujours ignoré ces raffinements (que Littré contestait déjà). »
[plus loin] « Hist. – C'est depuis qu'ils existent que second et deuxième s'emploient sans nuance distinctive. [...] »
Grevisse comme Littré ayant disons une certaine autorité en la matière, on ne voit pas pourquoi on ne se rangerait pas à leur interprétation. Ma'ame Michu 1 jul 2004 à 11:31 (CEST)
- (explication supplémentaire : cette question était motivée par http://fr.wikipedia.org/w/wiki.phtml?title=Wikip%C3%A9dia:Le_Bistro&diff=577512&oldid=577457 )
- Je suis entièrement d'accord avec Grevisse (le cas de second ~ deuxième est une tarte à la crème du français) mais ne vois pas trop pourquoi ce serait à moi de corriger. À moins que le but soit de faire en sorte qu'Hada de la Luna ne touche plus à cet article, ce qui en soi ne me gênerait pas : le lien que vous m'indiquez vers une ancienne version du bistro montre encore une fois son incompétence. Outre qu'apparemment elle ne connaît rien à la phonétique du vietnamien (je remarque que, pour l'instant, elle ne fait qu'affirmer qu'elle possède des connaissances, sans avoir jamais justifié une seule de ses remarques bancales), elle ne voit pas de quoi je parle quand j'évoque le ngo gai, quelle que soit l'orthographe du terme. Une simple recherche sur Google me renvoie 15600 pages... Vincent ✑ 5 jul 2004 à 01:23 (CEST)